Workload time series prediction in storage systems a deep learning based approach
论文名称
Workload time series prediction in storage systems: a deep learning based approach
Abstract
存储工作负载预测是实时和自适应集群系统中细粒度的负载平衡和工作调度的关键步骤。然而,如何进行基于深度学习方法的工作负载时间序列预测还没有得到深入研究。在本文中,我们提出了一种名为CrystalLP的基于深度学习的存储工作负载预测方法。CrystalLP包括工作负载收集、数据预处理、时间序列预测和数据后处理阶段。时间序列预测阶段是基于长短期记忆网络(LSTM)的。此外,为了提高LSTM的效率,我们研究了LSTM中超参数的敏感性。广泛的实验结果表明,与三种经典的时间序列预测算法相比,CrystalLP可以获得性能的提高。
The workload time series prediction framework based on deep learning
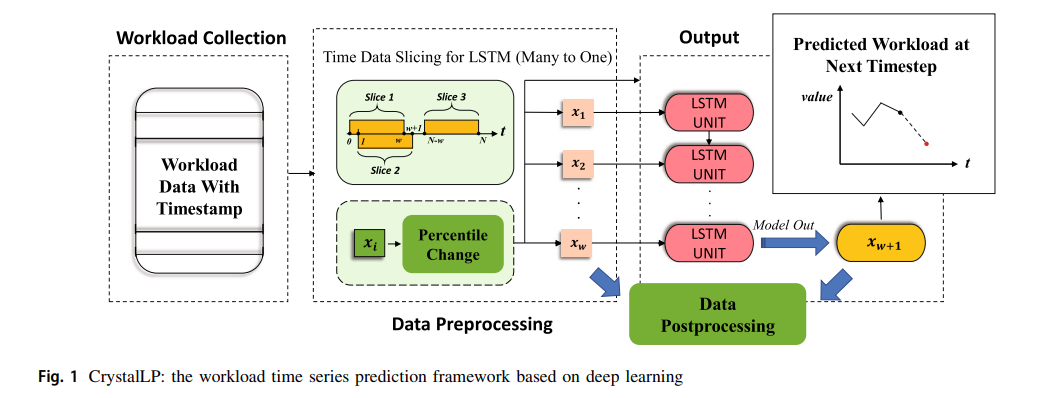
我们实用的存储系统工作量时间序列预测方法(图1)称为CrystalLP,包括工作负载收集、数据预处理、基于长短期记忆网络(LSTM)的时间序列预测和数据后处理。
The storage workload time series model
如何从实际trace数据中建立服务器负载时间序列模型是首先要解决的关键问题。根据时间定位原理,在一段时间内,由于程序倾向于运行相同的代码段来访问相同的数据,因此存储系统中的相同文件有可能被重复请求。换句话说,客户在访问某个数据服务器时,下次仍然有很大的概率访问同一个数据服务器。我们把这种现象定义为工作负载表现出某些模式,这将有助于精确和适应性的调度和负载平衡。因此,在本文中,我们将工作负载预测问题建模为一个单变量时间序列预测问题。
存储工作负载被定义为一个数据服务器在一个固定时期内的请求数据的大小(例如,字节)。因此,给定一个请求数据大小的时间序列,它被表示为。目标是学习函数,其中。而是时间的时间序列点,是历史水平线,指用于预测未来数据的多少个历史数据点,是预测水平线,指我们要预测多少个未来数据点。在本文中,为了方便清楚地介绍我们的方法,我们以单步预测为例。因此,预测水平线被设置为1。但当然,预测水平线可以根据用户的实际预测要求设置为合适的。
Autocorrelationn analysis of workload time series
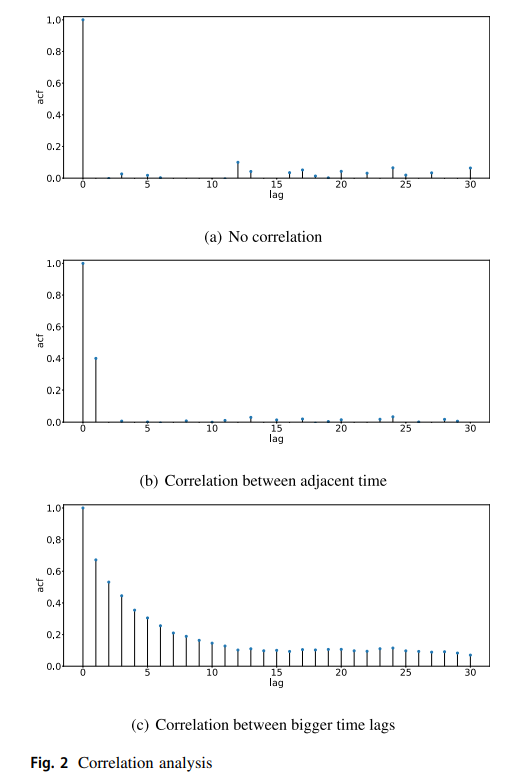
为了证明原理并解释在我们的方案中把工作负载预测问题建模为一个序列问题的原因,我们分析了一个流行的搜索引擎的文件系统工作负载的数据,称为WebSearch。该工作负载的细节将在第3.1节介绍。3.1. 我们主要使用自相关作为一种数学工具来分析存储时间序列的特征。自相关(公式1)描述了一个信号与自身延迟拷贝的相关性,是一个很好的工具来证明上面提出的想法。
例如,图2显示了三种不同的时间序列的自相关关系。在图2a中,除了时间滞后0的数值外,其他数值都接近于零,这意味着相邻的时间和更大的滞后期之间都没有相关性。信号更接近于白噪声,很难预测。在图2b中,除了时间滞后0和1的值外,其他值都接近于零,这意味着相邻时间之间有很强的关联性。而在图2c中,数值一般都比较大,这意味着相邻时间和较大的时间滞后之间存在相关性。对于图2a、c中显示的相关性,我们可以用一些函数来捕捉过去数据和未来数据之间的基本关系。所以这就是我们使用顺序模型预测大规模存储系统中的数据服务器的工作负荷的直觉。
The workload prediction model based on deep learning network
在第2.1节中,我们为工作负载预测问题建立了一个单变量单步时间序列预测模型后,如何使用适合服务器工作负载特征的适当的深度学习模型建立预测模型是一个关键步骤。正如上面所分析的,工作负载往往表现出复杂的模式。因为长短时记忆神经网络作为一个多对一的单元,具有适合复杂工作负载模式的优点,它适合捕捉历史范围和未来价值之间的内在关系。因此,我们选择LSTM网络作为例子来估计负载函数。是历史时间的工作量数据序列,即,每个是时间t的工作负载大小,其中设置为1,整个模型的输出代表下一个时间步骤的数据,也就是说我们把LSTM模型作为一个多对一网络。此外,为了在最后一个时间步长得到一个的向量,我们还在LSTM网络的末端添加了一个全连接层。如图3所示,LSTM单元的基本结构是由一个存储单元和三个基本门组成:输入门,遗忘门,输出门,其中是LSTM单元的隐藏神经大小,表示时间步长。
LSTM单元中的每个门和单元的状态在输入为的情况下根据公式2更新。
是时间的输入向量,是时间的隐藏状态向量。 是维度为的权重矩阵, 是前一个隐藏状态向量的权重矩阵。 状态向量ht1。LSTM模型各层的参数选择见表1。
表1是LSTM模型的各层参数。
Workload collection
在工作负载收集阶段,我们收集了由不同时间段的工作负载组成的工作负载时间序列数据。由于我们的模型主要用于单步工作量预测,这意味着在每个预测过程中,输入数据是历史范围内的数据,而模型的输出是下一个时间步骤的预测的工作量。
至于连续预测过程,我们使用算法1所示的滚动程序来处理。

其中,存储工作量时间序列被表示为的输入,预测的负载是想要的输出。T循环表示所采用的连续滚动预测模型,包括3个步骤。首先,对输入数据进行预处理并传送到预测模块。然后,获得负载预测的结果,并将其发送到后处理模块。最后,收集与该预测相对应的真实负荷值,将历史观察窗口向前移动,将窗口前面对应的负载加入到观察窗口中,并删除窗口后面的原始数据,开始下一次预测。随着整个循环的结束,也就是存储工作量时间序列的所有时间步骤都被处理完毕,最终得到想要的预测工作量。这个算法也被用于我们的测试集的实验中。
Preprocessing and postprocessing of workloads
在工作量时间序列预测过程中,我们遇到的第一个挑战是如何对工作量数据进行预处理,为时间序列预测构建一个合适的数据结构。
在数据预处理阶段,工作量数据将被一个长度为W的历史时间窗切开。随着时间窗沿时间轴的滑动,适合LSTM模型的工作量时间序列数据结构就建立了。
在实际的存储系统中,工作负载跟踪通常是在不同的时间段收集的,因此,在预评估阶段需要对原始跟踪进行一定的归一化操作,使其为进一步的特征分析和预测做好准备。因此,我们设计并对工作负载轨迹进行了一些规范化操作,例如将工作负载轨迹规范化为相同时间段的轨迹,观察和分析轨迹的稳定性,以便更好地找到一个子轨迹进行进一步的特征挖掘和参数调整等。在我们的实证研究中,我们设计了一个预处理模块,用固定的滑动窗口大小对序列数据进行切片,然后进行缩放变换,构建合适的数据作为输入。基于输入到输出的模型训练函数被设计为公式3。
如公式4所示,一个固定长度为的时间窗口被用来切分时间序列数据,以构建模型训练所需的输入和输出数据。
然而,I/O工作量具有很强的波动性,即在时间窗口内,不同的输入工作量值之间存在很大的差异,导致模型收敛困难。为了消除不同时间窗口内工作量数据的差距,使模型更容易学习,我们采用了基于窗口的归一化方法,如公式5所示,使同一窗口内的所有数据以第一个数据为参考,将预测振幅转化为预测增长率,从而减少训练数据的波动。
后处理采用反向收缩操作来恢复数据,最终得到预测值。
Model training
为了达到良好的模型训练效果,最近有人提出使用组合模型来训练深度学习模型。在我们的模型中,采用了minibatch随机梯度下降法(SGD)和Adam优化器来训练存储工作负载模型。minibatch的大小被设置为64。学习率被设置为0.001,这是根据的建议。通过标准的反向传播来学习参数,目标函数为平均误差平方,如公式6所示。
其中,是训练参数,是批次大小,最后一个等式中的第二项代表正则化,这将有助于避免过拟合。在验证集上early stop,确保模型被训练到合适。
Experiment
Introduction of I/O data source
在我们的测试中,第一个挑战是选择一个合适的存储I/O trace来验证我们的方法。虽然有很多公开发布的工作负载traces,如google trace, Alibaba trace,但它们更多的是与资源效用相关的工作负载跟踪,不适合存储I/O性能分析。
由于大部分的I/O trace没有公开发布,为了测试我们提出的模型,我们使用了一个叫做WebSearch1的数据集,它记录了一个搜索引擎的I/O。WebSearch档案是以一种特殊的格式保存的,称为SPC TRACE FILE FORMAT,它是为更好地分析跟踪而设计的。
根据Umass跟踪库文件(2007)1,跟踪文件中的每条记录代表一条I/O命令,由四个字段组成。第一个字段被称为应用特定单元(ASU),ASU是一个正整数,代表一个应用特定单元。第二个字段被称为逻辑块地址(LBA),LBA字段是一个正整数,描述该记录的数据传输的ASU块偏移。第三个字段是大小字段,它是一个正整数,描述这条记录传输的字节数。第四个字段称为Opcode,它记录了操作对应的读或写命令。第五个字段是时间戳,它是一个正数,代表这个I/O操作从跟踪开始的偏移量。所有字段的类型都在表2中描述。
Data preprocessing and model training
我们使用描述一条记录所传输的字节数的大小字段作为目标系列。请注意,大小字段同时适用于读和写操作请求,并由时间戳来追踪。
首先,由于工作负载跟踪没有自然地组织成一个存储I/O时间序列,我们从跟踪数据中选择档案来建立一个时间序列。在我们的实验中,我们以跟踪中的第一个归档文件为例,按照时间戳的字段组织跟踪。为了使时间痕迹正常化,我们将ASU0每1.0秒的请求数据的大小相加,生成一个单变量的请求时间序列。
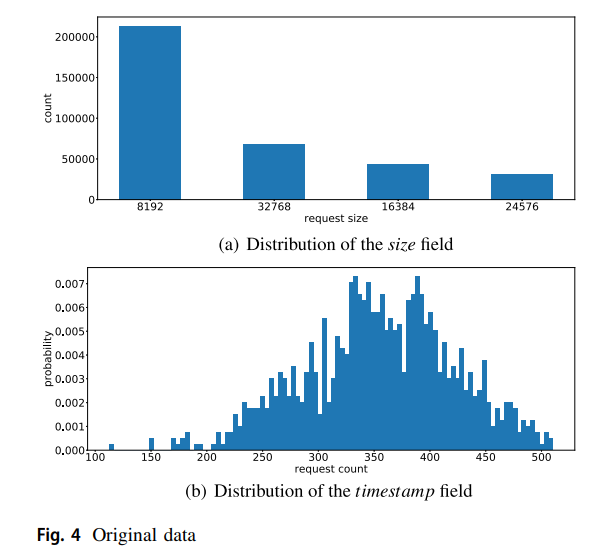
在工作负载痕迹被很好地格式化为存储工作负载时间序列后,对字段的分布(如大小和时间戳)进行分析。原始ASU0的数据的分析结果如图4所示。图4a显示在原始数据中有四种请求大小,最大的是8192字节。最小的是24576字节。中等的是32768字节和16384字节。
在我们的分析中,到达时间也是关键信息。因此,为了得到请求的到达时间,我们根据请求的时间戳将整个数据集均匀地分为1000个仓,并计算出每个仓的请求数。图4b显示了时间戳的分布。我们可以看到,每个仓的请求计数最多的范围是,而且数据的方差可能很大,这很难预测。上述分析验证了对存储工作负载跟踪进行预处理的必要性。此外,我们可以看到我们的上述分析是存储工作负载时间序列预测的基础。
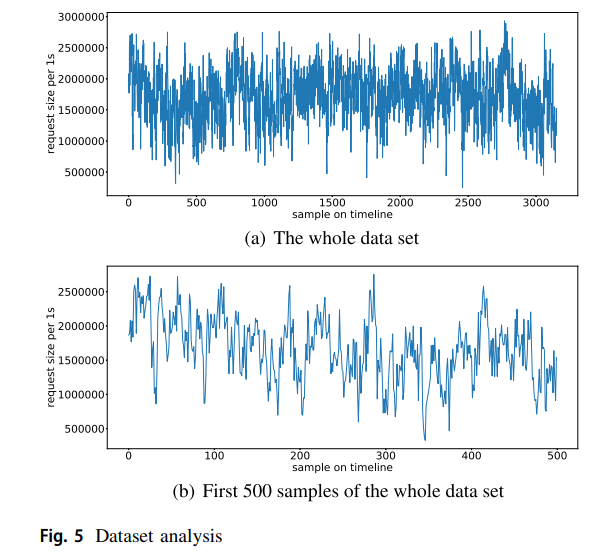
最后,建立了由前2488个数据点组成的训练集,由后面312个数据点组成的验证集和由最后351个数据点组成的测试集。该数据集如图5所示。其平均值为1711868.02,标准差为415512.83,最大值为2932736.00,最小值为262144.00。
如上所述,网络是为了学习函数。因此,我们首先用固定的窗口大小切割时间序列,并使用公式4作为我们的输入和输出对。为了将数值缩减到更小,使网络更容易学习,同时也约束数据的大小,我们再使用公式5中基于窗口的数据归一化方法。
Metrics
为了验证我们方法的有效性,考虑了公式7中三种不同的评价指标,即平均平方根误差(RMSE)、平均绝对误差(MAE)和平均绝对百分比误差(MAPE),其中模型的输出被表示为,ground truth被表示为。
Results: time series prediction
为了验证我们的方法,我们实施了三个经典的时间序列预测模型(第4节)作为比较基准。
对于基于ARIMA的工作量预测模型,我们用0.8.0版的python软件包statsmodels实现。我们首先使用Augmented Dickey-Fuller测试来分析工作负荷的固定性。然后,我们绘制了工作负载的自动相关和部分自动相关图,以确定参数p、i、q的大致范围。当我们根据训练集得到适当的p、i、q值时,我们就拟合一个ARIMA模型,然后预测测试集的未来值,然后将预测数据的基础事实收集到已知的数据集中,以扩大训练数据,然后根据扩大的训练数据拟合一个新的ARIMA模型。该循环将停止,直到测试集中没有数据需要预测。所以我们得到整个测试集的预测值。
对于SVR模型,我们使用Radial Basis Function作为核方法,这是一种主流的核方法,用0.19.1版的python包scikit-learn实现。除预测模型外,为了公平比较,我们使用了与上面讨论的工作量预测方法相同的程序。
对于我们的方法(模型2),我们在2.2.2版本的Keras中用python实现,对于Simple-RNN模型基线,我们只是用RNN单元替换我们的LTSM单元。

所有的模型都用python 3.6.6实现。最后,三个模型的实验结果显示在表3中。
在自适应I/O资源调度过程中,来自CrystalLP的预测工作负载值可以作为输入。
我们将CrystalLP的性能与三个经典模型,如Arima、SVR、SimpleRNN,在三个指标上进行比较,如RMSE、MAE和MAPE。从图3的实验结果中,我们可以发现Arima的RMSE为307629.58,比CrystalLP低0.89;MAE为250214.06,比CrystalLP低0.28;MAPE为0.1846,比CrystalLP低2.46。SVR的RMSE为304278.19,比CrystalLP低0.20;MAE为248345.99,比CrystalLP低1.03;MAPE为0.1840,比CrystalLP低2.20。SimpleRNN的RMSE为314267.07,比CrystalLP低2.98;MAE为258297.24,比CrystalLP低2.86;MAPE为0.1837,比CrystalLP低1.10。CrystalLP的RMSE为304894.7,MAE为250915.78,MAPE为0.1800。由于CystalLP是基线,所以没有它的数值。综上所述,预测结果(图3)表明,CrystalLP优于所有基线,MAPE至少提高了1.10%,而且在MAE和MAPE方面也有更好的表现。
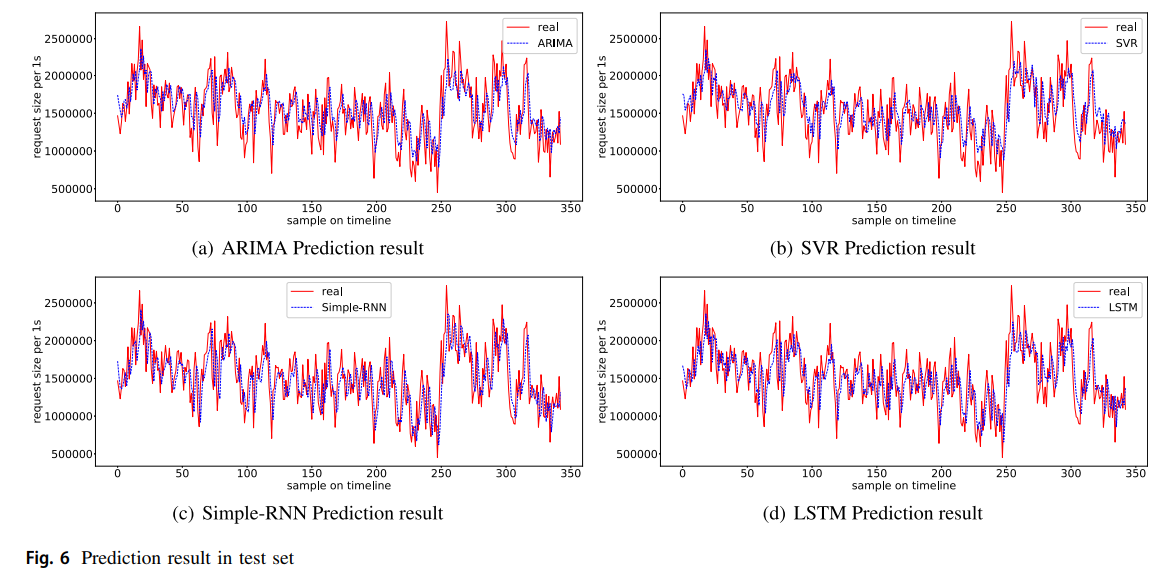
如图6所示,我们绘制了预测的工作量(每1s的请求大小)趋势,以比较ARIMA/SVR/Simple-RNN/LSTM(CrystalLP)对原始真实存储工作量的模型预测的生动效果。考虑到我们的时间序列数据是一个服务器在0.2s内的请求数据的大小,具有高频和复杂的相关性,我们认为能取得这样的改进是很了不起的。
Results: parameter sensitivity analysis
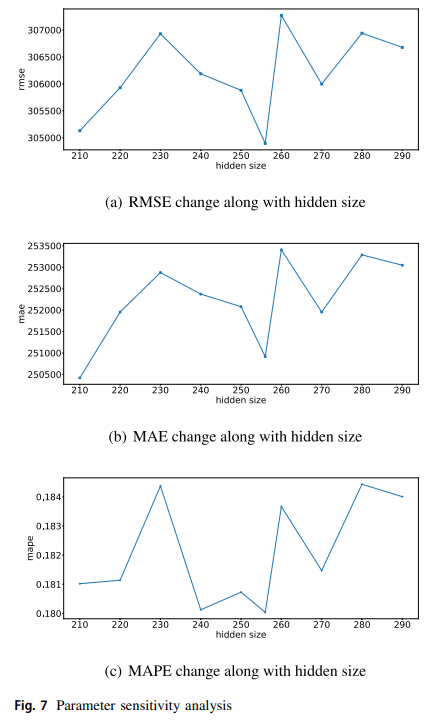
我们研究了LSTM中重要的超参数的敏感性,即隐藏大小。我们绘制了隐藏大小与RMSE、MAE和MAPE指标之间的关系,结果见图7。
从图7a中,我们可以看到,随着隐藏尺寸从210到290的上升,RMSE从大约305000增加到307000。随着hiddensize从210上升到290,MAE从250500左右增加到253500。随着Hiddensize从210上升到290,MAPE从大约0.181增加到0.184。综上所述,可以看出,随着隐藏规模的增加,各项指标有下降和上升的趋势。此外,当我们在图7中对三个实验进行比较时,RMSE在隐藏规模在250到260之间时达到了最佳性能。因此,参数敏感性分析结果证明,单纯增加网络规模来提高模型性能的想法是不合理的。正如我们在CrystalLP中提出的那样,结合粗粒度搜索和细粒度搜索的分层参数对于在存储工作负载分析中建立高变异存储工作负载的深度学习模型至关重要。
Related Work
许多学者试图克服工作负载预测中的问题。在过去十年中,有许多研究使用深度学习算法或基于统计的算法来预测负载。如上节所述,工作负载预测问题可以被看作是一个使用工作负载跟踪的时间序列预测问题。在本节中,我们首先回顾了计算时间序列分析的一些经典方法。然后,我们介绍了用于时间序列预测的人工智能方法。
Classic methods in time series analysis and prediction
工作负载时间序列分析是基于工作负载的平台性能分析方法的一个重要分支,如资源效用分析、任务失败分析等。然而,目前很少有方法专注于基于深度学习的存储工作负载分析。本文提出了一种基于深度学习的存储分析方法。
Classic methods in AI based workload analysis
现有的经典的工作量时间序列预测方法可以分为以下三类:统计学、基于机器学习和基于深度学习的方法。
The statistical method
在这一类中,自回归移动平均模型(ARMA)是最著名的一种。该模型可以捕捉静止序列中的线性关系,并通过差分方程的形式建立历史数据与未来数据之间的关系。而为了建立非平稳时间序列的模型,人们提出了自回归积分移动平均模型(ARIMA),作为ARMA的扩展,它可以通过差分技术解决非平稳时间序列的预测问题。我们在以前的工作中开发了一个ARIMA模型的在线变体来预测I/O的工作量。Di等人提出了一个基于观察窗口内统计特征的贝叶斯模型来预测谷歌云服务集群中服务器的CPU使用率。而CrystalLP是我们使用深度学习模型的新尝试。
The machine learning method
随着机器学习的发展,时间序列预测已经被表述为一个回归问题,通常可以通过支持向量回归(SVR)来解决。SVR可以通过非线性变换将输入空间映射到特征空间,从而捕捉到输入和输出之间的关系。此外,通过核方法(如RBF),SVR可以很容易地处理维数诅咒问题,更好地利用高维特征空间。此外,Neelima等人提出了一种新型的自适应蜻蜓算法(ADA)来完成云负载平衡中的NPhard优化问题。
The deep learning method
长短期记忆(LSTM)网络克服了梯度消失的问题,因此可以捕捉到长期的依赖性。最近,LSTM被应用于预测云环境中的CPU使用率。2018年,Zhang等人使用时间序列聚类算法结合双向长期和短期内存网络来预测服务器的CPU效用;2019年,Duggan等人提出了一个基于递归神经网络的服务器CPU和网络带宽占用预测,以帮助云环境中的虚拟机迁移。Gupta等人首次使用在线稀疏Bi-LSTM来解决相同的云工作负载预测问题,Gao等人采用类似的模型来识别云中的任务和工作故障。最近,一些更复杂的模型结构与深度学习相结合被提出。Peng等人开发了一个新颖的预测框架,称为编码器解码器,对云工作负载进行多步骤的预测。Zhang等人提出了一个高效的基于典范多态分解的深度学习模型来预测行业的工作量。
Conclusion
在本文中,我们提出了一个实用的基于深度学习的方法,称为CrystalLP,用于预测存储系统中的工作负载。广泛的实验结果验证了CrystalLP在RMSE、MAE和MAPE方面取得了比三种经典时间序列预测算法更高的性能。据我们所知,我们是第一个将深度学习方法引入服务器负载分析的人。根据我们的实践,我们预测如何将人工智能方法,如深度学习方法,应用于大系统的性能挖掘将是一个有前途的研究方向。其他基于深度学习的存储工作负载分析的设计是我们正在进行的和未来的工作。