ResNet
论文名称
Deep Residual Learning for Image Recognition
摘要
深的神经网络难以训练,作者提出残差学习的框架,使训练非常深的网络比之前容易很多。将各层重新表述为学习参考层输入的残差函数,而不是未参考的函数。
实验效果:在ImageNet数据集上评估152层的网络,比VGG深8倍,但复杂度要低于VGG。实验取得了3.57%的误差,在2015年ILSVRC分类任务获得第一名,此外还有100层和1000层CIFAR-10的实验分析。
网络的深度对很多计算机视觉任务非常重要,由于网络设置的非常深,作者在COCO物体检测数据集获得28%的改进,此外还赢得了ImageNet检测、ImageNet定位、COCO检测和COCO分割等任务的第一名。
Introduction
深度卷积神经网络在图片分类上取得了很大的突破,并且深度网络自然的将低中高的特征和分类器以端到端的形式整合,并且可以通过堆叠层数,深度来丰富特征的层次。
网络的深度非常重要,但是作者抛出了一个问题:Is learning better networks as easy as stacking more layers?
当网络很深时,容易出现梯度消失、梯度爆炸等问题,解决方案:1.初始化的权重不宜过大也不宜过小 2.在中间加入Normalization,例如BN等,可以校验每个层之间的输出和他的梯度的均值和方差。避免有些层过大,有些层过小。
使用上述方法可以使网络收敛,这时一个次要的问题就暴露出来了。随着网络的深度增加,准确度会达到饱和,然后迅速退化,这种退化并不是由于过拟合引起的,而在一个适当的深度模型上增加更多的层会导致更高的训练误差。如图,当网络的深度增加时,train error和test error都在增加。虽然网络收敛了,但训练的效果不理想。
因此简单的堆叠层数,并不能优化网络的性能,对一个浅层网络,在它的基础上添加更多层,例如增加层仅仅是一一对应,例如输入x,输出x,增加网络的层数至少不应该会降低网络的性能。但实验表明我们目前的优化器无法找到这样的解决方案。
本片论文主要通过引入深度残差学习框架解决退化问题。作者不希望几个堆积层直接训练所需的底层映射,而是让这些层训练一个剩余的映射。
解释:意思为作者不希望堆叠后的网络直接训练出来,因此作者希望堆叠出来的层,训练,而此时浅层仍然 为此时原始映射就变成了。
个人理解:x为浅层网络学习到表征,经过堆叠的层后得到的映射为,但不让这个堆叠的网络直接训练得到,因为直接学习到的很有可能效果不如浅层网络,因此希望它学习,这个函数更易于优化,假定此时恒等映射更好,即,那么可以使堆叠的网络学习到的为,即将残差部分推到0,此时,此时至少可以保证效果不低于浅层网络,若堆叠的层获得了更好的表征,很有可能提升网络的性能。
如图: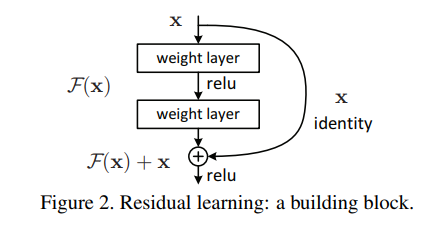
因此,可以被认为是有捷径的连接的前馈神经网络。并且只是简单的连接,因此不增加额外的参数,也不增加计算的复杂性,整个网络仍然可以通过SGD反向传播进行训练。
ResNet在ILSVRC2015获得了第一名,top-5的错误率为3.57%。此外极深的网络增强了表征能力,获得了ImageNet定位、COCO检测的第一名。
ImageNet、CIFAR10上的实验表明:
- 具有残差连接的网络很容易优化,而普通的网络容易表现更高的误差。
- 深度的残差网络可以获得网络深度增加带来的性能提升,结果远远优于以前。
深度残差连接网络
残差学习
网络结构
如何处理输入和输出不一致的情况:
- 在输入和输出上分别添加0在额外的维度上,这种方法可以减小参数。
- 使用1*1的卷积核并设置步长,使通道数、高宽对齐。
实验相关设置
网络相关设置:
- 对每次卷积操作后,激活函数之前采用Batch Normalization。
- batch-size = 256.
- learning rate = 0.1, 当错误率比较平滑时除以10.
- weight decay = 0.0001, momentum = 0.9.
- 不使用dropout.
数据处理:
- 将ImageNet的数据集,图像的短边放到,并对其水平翻转,再进一步对原图像采样或水平翻转后的图像采样,并减去每个像素的平均值。同时使用标准色彩增强。这样在将图像裁剪为224*224时候,随机性更强。
- 测试时,按照一定规则采样十张图片(包含将最短边按照[224,256,384,480,640]缩放),将得到的分数平均。
实验
ImageNet
ImageNet2012数据集包括1000分类,模型在128万图片下训练,并在5万张图片上验证,最终在10万张图片上测试。
Plain Networks:首先评估18层和34层的普通网络。网络结构下图所示。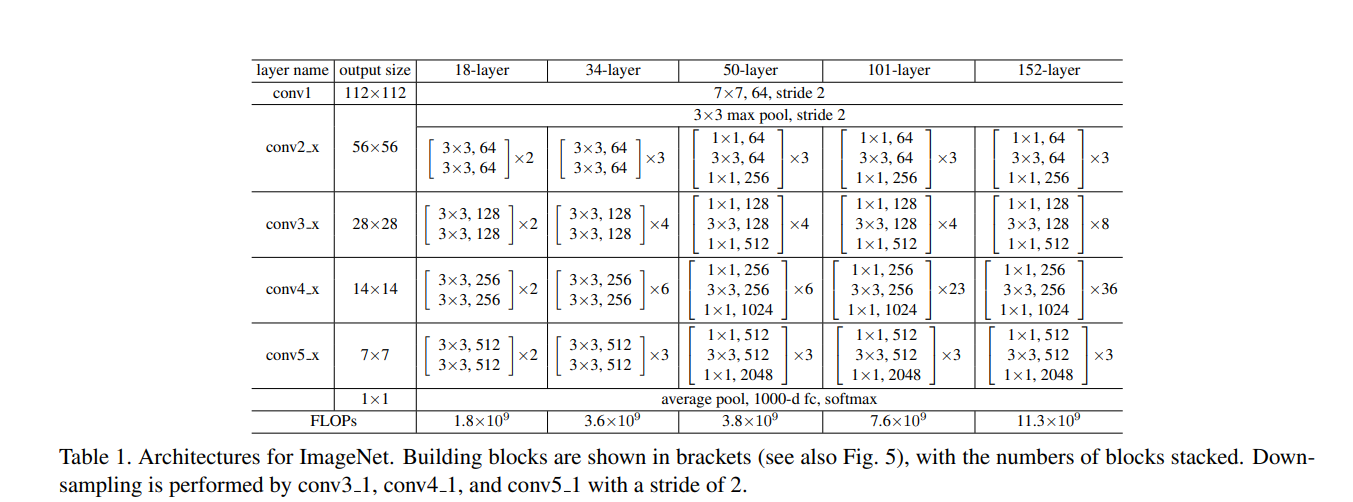
实验结果如下图所示,结果表明较深的34层比较浅的18层网络的验证误差要高。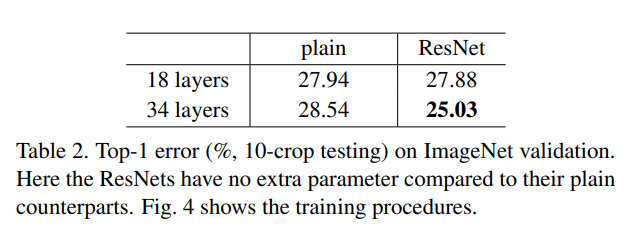
由于使用了Batch Normalization,这种优化的困难不太可能由于梯度消失引起。
下图中,我们可以观察到,由于训练时运用了大量数据增强的方法,一开始train(红色)的error要高于验证集,而验证集上噪音较低。由于SGD的优化,两次跳跃为学习率*0.1。(炼丹技巧:前期进入平滑时可以继续平滑一会儿后再将学习率降低) 同时有残差连接,收敛的更快。 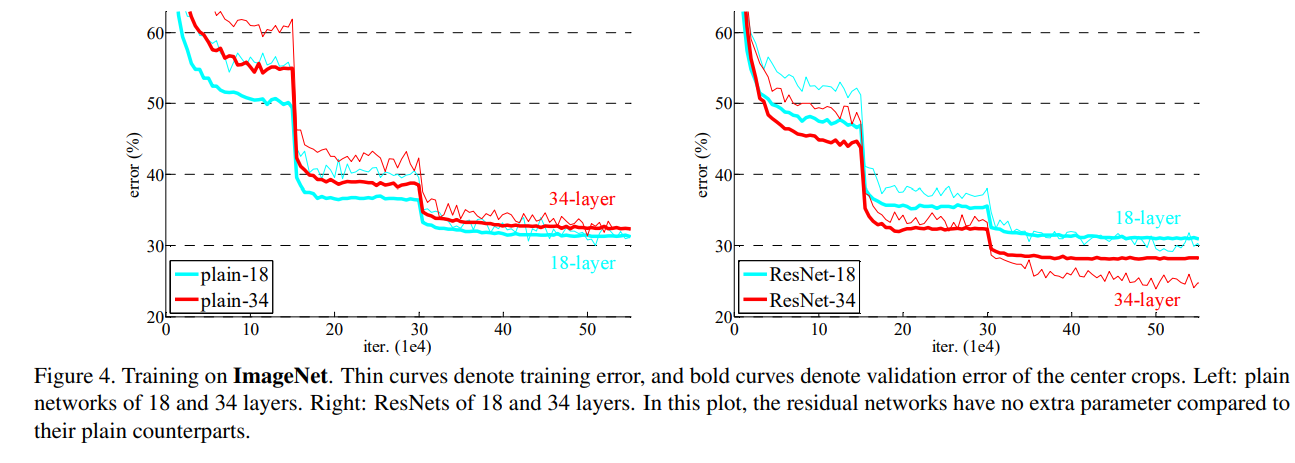
代码实现
Basic Block的实现
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.basicblock = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=False),
nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
)
self.relu = nn.ReLU(inplace=False)
self.downsample = downsample
def forward(self, input):
residual = input
x = self.basicblock(input)
if self.downsample:
residual = self.downsample(residual)
x += residual
x = self.relu(x)
return x
Bottle Neck的实现
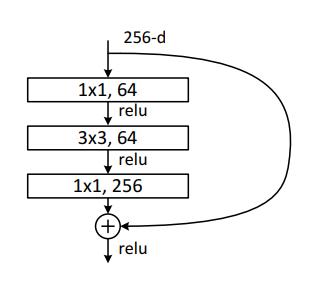
class BottleNeck(nn.Module):
# 维度扩张
expansion = 4
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super(BottleNeck, self).__init__()
self.bottleneck = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=False),
nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=False),
nn.Conv2d(out_channels, out_channels * self.expansion, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels * self.expansion),
)
self.relu = nn.ReLU(inplace=False)
self.downsample = downsample
def forward(self, input):
residual = input
x = self.bottleneck(input)
if self.downsample:
residual = self.downsample(residual)
x += residual
x = self.relu(x)
return x
ResNet各个版本的实现
class ResNet(nn.Module):
"""
ResNet的具体实现
"""
def __init__(self, block, num_layer, n_classes, init_weights=True):
super(ResNet, self).__init__()
self.in_channels = 64
# 定义网络结构
self.conv1 = nn.Conv2d(in_channels=3, out_channels=64, kernel_size=7, stride=2, padding=3, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.maxpool = nn.MaxPool2d(3, stride=2, padding=1)
self.relu = nn.ReLU(inplace=False)
self.layer1 = self._make_layer(block, 64, num_layer[0])
self.layer2 = self._make_layer(block, 128, num_layer[1], 2)
self.layer3 = self._make_layer(block, 256, num_layer[2], 2)
self.layer4 = self._make_layer(block, 512, num_layer[3], 2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.flatten = nn.Flatten()
self.fc = nn.Linear(512 * block.expansion, n_classes)
if init_weights == True:
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode="fan_out", nonlinearity="relu")
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def _make_layer(self, block, out_channels, num_block, stride=1):
downsample = None
if stride != 1 or self.in_channels != out_channels * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channels, out_channels * block.expansion, 1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels * block.expansion)
)
layers = []
layers.append(block(self.in_channels, out_channels, stride, downsample))
self.in_channels = out_channels * block.expansion
for _ in range(1,num_block):
layers.append(block(self.in_channels, out_channels))
return nn.Sequential(*layers)
def forward(self, inputs):
x = self.conv1(inputs)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = self.flatten(x)
x = self.fc(x)
x = F.softmax(x, dim=1)
return x
def ResNet18(n_classes: int):
"""
构造ResNet18模型
:return: ResNet18
"""
model = ResNet(block=BasicBlock, num_layer=[2, 2, 2, 2], n_classes=n_classes)
return model
def ResNet34(n_classes: int):
"""
构造ResNet34模型
:return: ResNet34
"""
model = ResNet(block=BasicBlock, num_layer=[3, 4, 6, 3], n_classes=n_classes)
return model
def ResNet50(n_classes: int):
"""
构造ResNet50模型
:return: ResNet50
"""
model = ResNet(block=BottleNeck, num_layer=[3, 4, 6, 3], n_classes=n_classes)
return model
def ResNet101(n_classes: int):
"""
构造ResNet101模型
:return: ResNet101
"""
model = ResNet(block=BottleNeck, num_layer=[3, 4, 23, 3], n_classes=n_classes)
return model
def ResNet152(n_classes: int):
"""
构造ResNet152模型
:return: ResNet152
"""
model = ResNet(block=BottleNeck, num_layer=[3, 8, 36, 3], n_classes=n_classes)
return model
参考文献
[1] PyTorch实现ResNet
[2] PyTorch visions [3] Deep Residual Learning for Image Recognition