FaceNet
论文名称
FaceNet: A Unified Embedding for Face Recognition and Clustering
会议: CVPR2015
将输入图像嵌入为欧式空间中的特征向量,利用欧式距离衡量两个特征向量间的欧式距离。进而可以用在人脸验证、识别和聚类任务中。
起因
读这篇论文的动机是最近在声纹识别处理遇到了问题,在声纹识别的处理中,将声音做嵌入。 项目在一开始没有找到合适的损失函数,导致优化目标不明确, 后来在网上搜索后,查找到相关的损失函数triplet loss,它最早在FaceNet论文中提出,因此详细阅读FaceNet很有必要。
摘要
提出FaceNet的系统,它学习脸部图像到紧凑的欧几里得空间的映射,使得可以通过距离来计算人脸相似度。我们可以进一步利用FaceNet做图像嵌入实现人脸验证、识别、聚类等任务。
使用深度卷积神经网络训练优化图像的Embedding.
为了训练这个网络,使用一种三元组的方法。
同时还引入了harmonic Embeddings和harmonic triplet loss,用于描述不同网络的不同版本的图像嵌入,他们互相兼容,并可以直接比较。
Introduction
提出FaceNet :人脸验证(is this the same person)、人脸识别(who is this person)、人脸聚类(find common people among these faces)
基于深度CNN为每个图片建立一个欧式图像嵌入,因此可以比较欧式距离。
之前的工作:使用已知身份的人脸图像集训练一个分类模型,取某个层作为人脸的特征表示,但是泛化能力很差,且维度很高。
不同之处:FaceNet将输入图像输出为128维更加紧致的嵌入,使用三元组损失函数。这个三元组损失函数,包括两张匹配的人脸和一张不匹配的人脸图。loss的目标是使正例和负例有一定的距离。
选择合适的三元组:提出一种新的负样本的挖掘策略,持续增加三联体的难度。提高聚类的准确性,提出hard-positive挖掘方法,鼓励对一个人进行球状聚类。(聚类这里存疑)
图示:阈值为1.1时,可以较好的分出三个人。
Related Work
Inception、深度卷积网络+SVM等方法。
Method
讨论两种核心模型: ZFNet、Inception。
将他们视为黑盒,将他视为端到端的系统,在模型的输出后,使用triplet loss。 即对于一张图片来说,经过网络的处理,将图像变换成的空间的向量。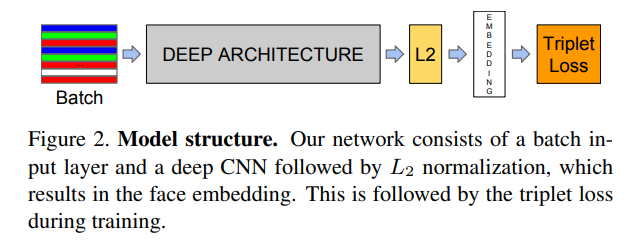
目标:所有相同身份的人脸之间的平方距离很小,而来自不同身份的一对人脸图像之间的平方距离很大。
三联体损失函数更加适合人脸验证,它增强不同人之间的脸的间隔,这使得同一个人的脸即使在不同情况下,其欧式距离也会小于其他人。
三联体损失函数
image:
embedding:
embedding层将图像转化为一个维的欧式空间的向量。
我们想要确保一个三元组为(anchor,positive,negative)中anchor对于positive中的所有样本比negative的样本更加接近。
因此我们希望,为margin、为所有可能的三联体的集合,为基数:
此时Loss为:
由于部分三联体很容易满足上述要求,因此会导致网络收敛较慢,因此选择三联体非常重要。
三联体选择
为了确保快速收敛,关键在于违反约束的三联体。
给定,我们想要选取(hard positive),。
相似的,选取(hard negative),.
在整个训练集上计算argmax和argmin是不可行的,一些错误的标签和糟糕的图像会导致hard positive和hard negative。
解决方法:
- 离线:每隔n步生成三联体,计算数据子集上的argmin和argmax。
- 在线:从一个小批次中选择hard positive和hard nagative示例来完成。
作者这里使用的minibatch规模较大,且要确保任何一个身份都有最小样本数存在,每个身份在每个minibatch大约有40张脸,negative face通过随机抽样被添加到每个minibatch中。
在训练过程中,使用minibatch中所有正样本对,但仅使用hard negative,选择最难的负例对可能在训练初期收敛到一个较差的局部最小值,特别是收敛到一个崩溃的模型。
选取hard negative的规则:
这些例子被称为semi-hard,因为他们比正面的例子离anchor更远,但仍然是hard的,因为距离的平方接近于anchor的正向距离,这些负例位于边界内。
三元组的选择对模型训练至关重要,使用小的minibatch的SGD收敛更快,实现的时候,大一点的minibatch使用向量化计算也会加速,作者常用的minibatch大小为1800.
深度卷积神经网络
实验中作者使用SGD、标准的backprop、AdaGrad训练CNN。学习率初始设为0.05,逐渐下降,模型采用随机初始化的方式。被设置为2.
在CPU集群上训练1,000到2,000小时。损失的减少(和准确度的提高)在训练500小时后急剧减慢。训练500小时后,损失的减少(和准确率的提高)明显放缓,但额外的训练仍然可以显著提高性能。
作者主要使用ZFNet和GoogleNet,ZFNet添加了11d的卷积核,有1.4亿参数,每幅图像前向计算量为1.6Billion次浮点运算。
还使用了GoogleNet。参数相比第一种网络少了20倍,计算量相比第一种网络少了五倍,作者定义了NNS1 ~ NNS4四种小网络。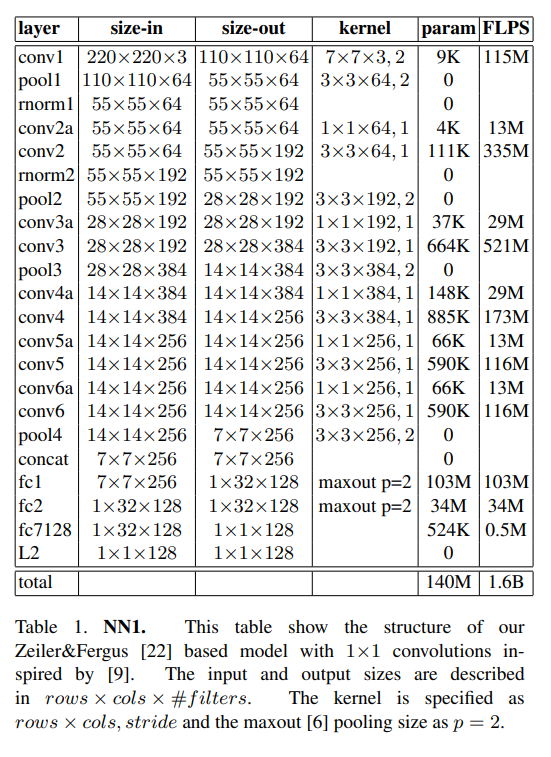
数据集和评价指标
在LFW和YTF数据集上进行人脸验证任务的评价。 图像对的欧氏距离表示为,对于人脸对,相同身份被标记为,不同身份被标记为
d被设定为人脸是否相似的阈值。
验证准确率:
错误接受率:
实验
作者使用100M-200M的训练脸部缩略图,包括大约8百万个不同的身份。
以下为部分实验结论:
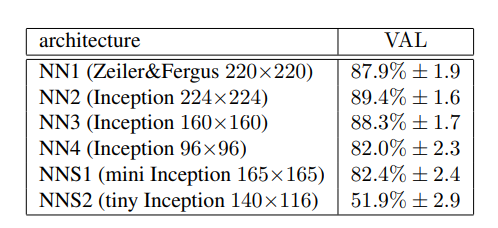
- 不同的网络
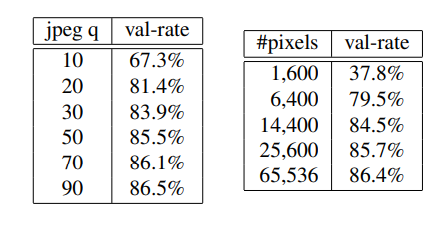
- 图像的质量
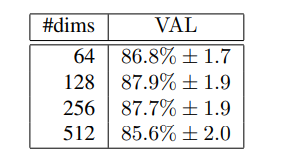
- 嵌入的维度
总结
作者主要提出基于三元组的损失函数,实现了FaceNet,重点在于三元组的选取。