AlexNet
论文名称
ImageNet Classification with Deep Convolutional Neural Networks
摘要
在ImageNet LSVRC-2010比赛上,在测试集上,top-1的错误率为37.5%,top-5的错误率为17.0%。在ILSVRC-2012比赛上,以top-5的错误率为15.3%赢得第一名,第二名为26.2%。在AlexNet提出后,vgg、Inception等网络相继被提出,影响深远。
神经网路有600million参数,650000神经元。
为了减少过拟合,使用了正则化方法"dropout"。
介绍
当前的方法大多是基于机器学习的方法,为了提升它的表现,使用更大的数据集、更好的方法,简单的识别任务已经可以做的很好了,但是对于大型的数据集对象识别仍然是个困难的问题。
为了从数百万张图片中学习数千个物体,使用了一个大的卷积神经网络。并使用在ILSVRC-2010,ILSVRC-2012比赛上,实现了最好的结果。
作者主要写了高度优化的2维卷积的GPU实现。此外网络还用了一些新的不常用的方法使效果更好。 网络过大时候容易过拟合,使用了有效的技巧防止过拟合。 最后的网络有五个卷积层、三个全连接层。 由于网络大小限制,将整个网络,切为两部分。
数据集
ImageNet的数据量超过1500万的数据量,大约有22000类。
从2010年起,ILSVRC竞赛被举办,1000类,每类有1000张图片,训练集大约为1.2million,验证集大约为50000,测试集大约为150000.
数据预处理部分,主要将数据下采样,形成256*256的固定大小,将短边缩放为256,将长边中心裁剪为256。此外使用原始RGB作为输入,形成端到端的模型。
模型结构
ReLU非线性激活函数
作者主要选取了ReLU函数作为激活函数,根据作者的描述,使用这种激活函数,会使网络收敛的更快。
在多个GPU训练
由于GTX580只有3G内存,需要将网络切分。 作者花了很大的篇幅来描述如何在两个GPU上训练。随着GPU的发展,对于简单网络,可以以更容易的方式训练,本次读论文不详细关注实现的细节。
Local Response Normalization
LRN的公式如下:
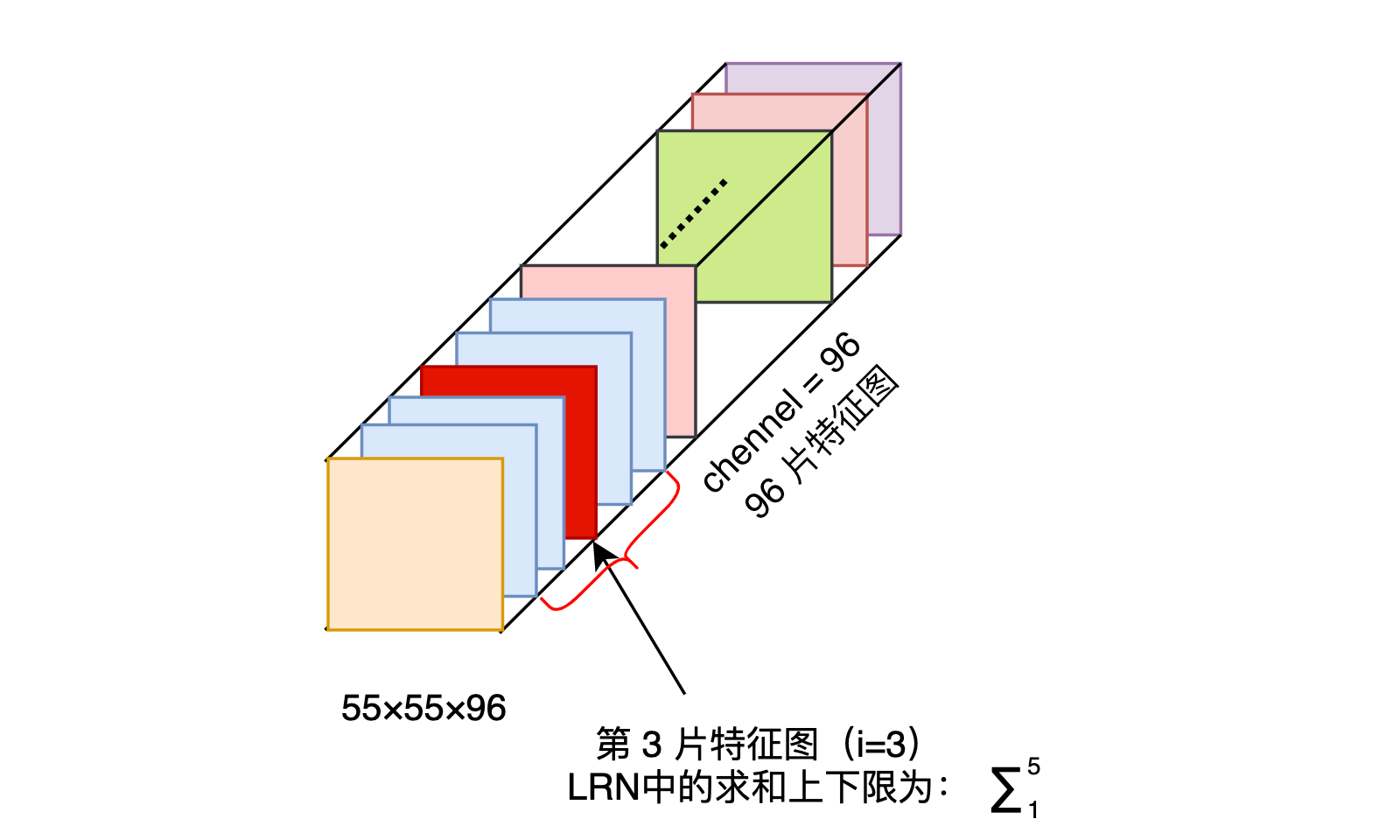
其中a表示为卷积层(卷积和激活)后输出的结果,输出的结果为,以为例,其表示为第张图片,第个通道,高度为,宽度为的点。表示为第个特征图在位置处应用ReLU后的输出,是同一位置上临近的特征图的数量,是特征图总数。
笔者在实际写AlexNet时,看过PyTorch的AlexNet实现,tochvision中的AlexNet将LRN部分删除,在后续的一些研究中显示,LRN对模型的泛化能力没有特别的作用,甚至会导致模型准确率降低,且LRN引入了较多的超参,调参困难。
overlapping pooling
池化层总结了相邻的神经元的信息,但传统的池化层所总结的邻域并不重叠,作者采用重叠池化,将传统的(s=2,z=2)修改为(s=2,z=3),其中s为步长,z为窗口大小。
Overall Architecture
网络的整体结构如下如所示: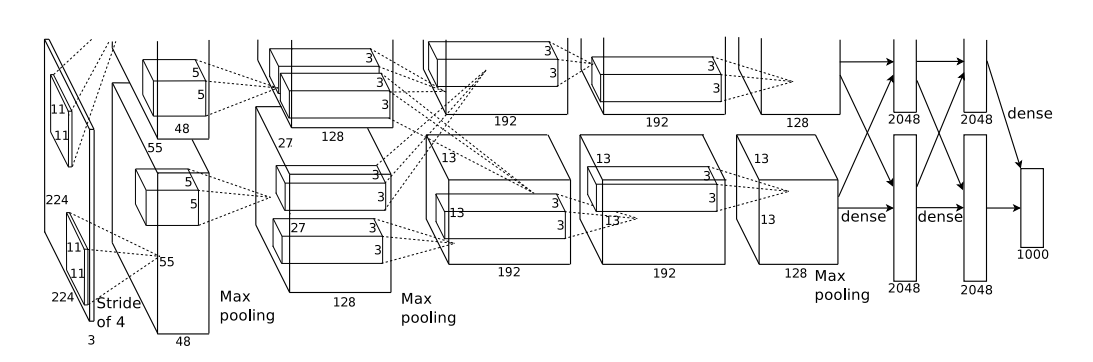
网络整体由五层卷积层,三层全连接层,最后通过1000路的softmax。
第二层,第四层,第五层的卷积层只和前一层的结果相连接,这些结果位于一个GPU上。第三层与第二层的所有结果相连接。ReLU非线性激活函数被用于每个卷积层和全连接层的输出。LRN层在第一层和第二层卷积后。Overlapping Pooling层紧随LRN层和第五层卷积层后。
减少过拟合
数据增强
对图片做镜像反射,将处理后的图片随机裁剪出227*227的块。两步操作如下图所示。


作者表示通过这种方式时数据集增大了2048倍,但由此产生的数据产生高度依赖,不适用这种方法会导致严重过拟合,在AlexNet中抽取测试样本及其镜像反射图各5块(总共10块,四个角和中心位置)来进行预测,预测结果是这10个块的softmax块的平均值。
但在OverFeat文章中提到,这样裁剪测试的方法会忽略掉图片中的很多区域,并且从计算角度讲,裁剪窗口重叠存在很多冗余的计算,另外,裁剪窗口只有单一的尺寸,这可能不是ConvNet的最佳置信度的尺寸。改变训练样本RGB通道的强度值 Alex团队在整个训练集中对图片的RGB像素值集执行PCA。对于每一张训练图片,他们增加了多个找到的主成分,它们的大小比例是相应的特征值乘以一个随机值.
Dropout
作者设置的。作者认为使用这种方法可以提供模型的融合,Dropout现在看来更像是正则项。
学习的细节
AlexNet使用随机梯度下降算法,batch大小是128,动量衰减参数,权重衰减参数,这里的权重衰减不仅仅是一个正规化器,同时它减少了模型的训练误差。更新的公式如下:
其中是迭代次数,是momentum variable,是学习率,是第个batch的目标对的导数的平均值。
在AlexNet中,所有层的权重初始化为服从0均值,标准差为0.001的高斯分布,第2、4、5卷积层以及全连接层的偏置量初始化为1,好处是通过给ReLU函数一个正激励从而加速早期学习的速度。其他层的偏置量初始化为0.
讨论
结果显示深度的神经网络能够在非常有挑战性的数据集上,实现非常好的结果。 而当去掉一层卷积层后,效果会下降2%,所以深度非常重要。
现在看来,深度很重要,同时参数也非常重要,注意深度的同时也要注意宽度。
总结
AlexNet在被提出后,对深度学习影响深远,其在CNN中成功应用了ReLU、Dropout和LRN等Trick。同时AlexNet也使用了GPU进行运算加速,对后面分布式训练也起到了启发的作用。