Incorporating Hierarchy into Text Encoder
论文名称
会议:ACL2022
Abstract
由于标签层次结构复杂,分层文本分类是多标签分类的一项具有挑战性的子任务。现有的方法分别对文本和标签层次结构进行编码,并混合它们的表示形式进行分类,其中对于所有输入文本,层次结构保持不变。在这项工作中,我们提出了分层引导对比学习(HGCLR),而不是分别建模它们,直接将分层嵌入到文本编码器中。在训练过程中,HGCLR在标签层次结构的指导下,为输入文本构建正样本。通过将输入文本和它的正样本放在一起,文本编码器可以学习独立地生成支持层次结构的文本表示。因此,经过训练,HGCLR增强文本编码器可以省去冗余的层次结构。在三个基准数据集上的大量实验验证了HGCLR的有效性。
Introduction
分层文本分类(HTC)旨在将文本分类为一组标签,这些标签组织在结构化的层次结构中。分类层次结构通常建模为树或有向无环图,其中每个节点都是要分类的标签。作为多标签分类的子任务,HTC的关键挑战是如何建模大规模、不平衡和结构化的标签层次。
HTC现有的方法采用了多种引入层次信息的方法。在最近的研究中,最先进的模型分别对文本和标签的层次结构进行编码,并聚合两种表示,然后用混合特征进行分类。 如下图左侧所示(文本和标签分开,混合表示),它们的主要目标是在文本和结构之间充分交互,以实现混合表示,这对分类非常有用。然而,由于标签层次结构对所有文本输入保持不变,因此图形编码器提供了完全相同的表示,无论输入是什么。 因此,文本表示与恒定的层次结构表示相互作用,因此交互似乎是多余的和不太有效的。我们尝试将常量层次结构表示注入文本编码器。因此,在完全训练后,可以获得一个层次感知的文本表示,而不需要常量标签特征。 正如下图的右边部分所示(将层次信息纳入文本编码器,实现层次感知的文本表示),不是分别建模文本和标签,而是将标签层次结构迁移到文本编码中,通过适当的表示学习方法可以使HTC受益。 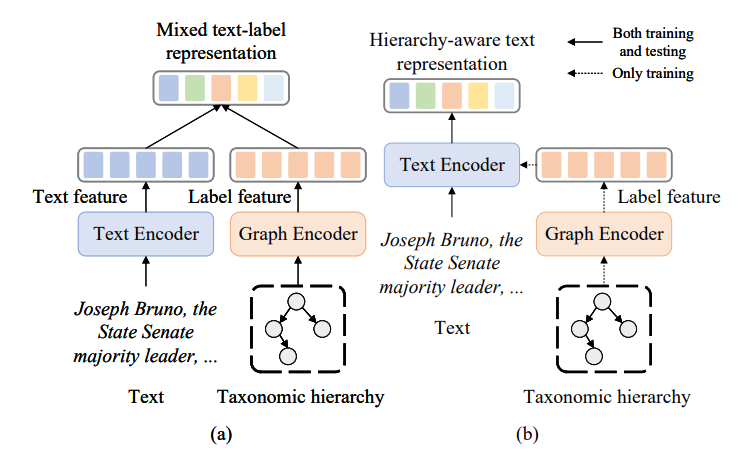
为此,我们对层次感知表示采用对比学习。对比学习旨在集中正样本和推开负样本,被认为是构建有意义表征的有效方法。以前关于对比学习的研究表明,对比学习对构建具有挑战性的样本至关重要。对于多标签分类,我们试图构建高质量的正例子。现有的正例生成方法包括数据增强、dropout和对抗性攻击。这些技术要么是无监督的,要么是特定于任务的:正例样本的生成与HTC任务没有关系,因此无法获得层次感知的表示。如前所述,我们认为对于HTC任务,应该同时考虑真实标签和分类层次结构。
为了构建既具有标签导向又具有层次关系的正例样本,我们的方法是由初步观察推动的。请注意,当我们将文本分类到某个类别时,大多数单词或标记都不重要。例如,当一段关于最近一场体育比赛的新闻报道被归类为“篮球”时,“NBA”、“篮板”等关键词的影响较大,而比赛结果的影响较小。因此,给定一个序列及其标签,只保留几个关键字的缩短序列应该维护标签。这种想法类似于对抗性攻击,目的是寻找对分类影响最大的“重要标记”。不同的是,对抗性攻击试图修改“重要的标记”来欺骗模型,而作者的方法修改“不重要的标记”来保持分类结果不变。
基于上述表述,我们构建了正样本作为输入序列对和它们的缩短序列对,并提出了针对HTC的层次引导对比学习(HGCLR)。为了定位给定标签下的关键字,直接计算每个标签上嵌入的每个token的注意力权值,认为权值超过阈值的令牌对参考标签很重要。我们使用一个图形编码器来编码标签层次结构和输出标签特性。与之前使用GCN或GAT的研究不同,我们修改了一个Graphormer作为我们的图形编码器。Graphormer通过Transformer块编码图形,在一些与图形相关的任务上优于其他图形编码器。它从多个维度建模图形,可以方便地为HTC任务定制。
主要的贡献有:
- 提出层次引导对比学习(HGCLR)来获得HTC的层次感知文本表示。这是HTC上第一个采用对比学习的作品。
- 对于对比学习,通过标签层次结构指导的新方法构建正样本。该模型采用了改进的Graphormer,这是一种新的最先进的图形编码器。
- 实验表明,本文提出的模型在三个数据集上都实现了改进,代码链接。
Related Work
层次文本分类
根据对待标签层次结构的方式,HTC现有的工作可以分为局部和全局方法。局部方法为每个节点或级别构建分类器,而全局方法仅为整个图构建一个分类器。Banerjee等人为每个标签建立一个分类器,并将父模型的参数传递给子模型。Wehrmann等人提出了一种结合局部优化和全局优化的混合模型。Shimura等人应用CNN利用上层的数据来帮助下层的分类。
早期的全局方法忽略了标签的层次结构,将问题视为扁平的多标签分类(Johnson and Zhang, 2015)。随后,一些工作试图通过递归正则化(Gopal和Yang, 2013)、强化学习(Mao等人,2019)、胶囊网络(Peng等人,2019)和元学习(Wu等人,2019)来合并标签结构。虽然这种方法可以捕获层次信息,但最近的研究表明,通过结构编码器直接对整体标签结构进行编码可以进一步提高性能。Zhou等人(2020)设计了一种结构编码器,该编码器集成了标签先验层次知识来学习标签表示。Chen等人(2020a)在双曲空间中联合嵌入词和标签层次结构。Zhang等人(2021)根据不同层次提取文本特征。Deng等人(2021)引入信息最大化来约束标签表示学习。Zhao等人(2021)设计了一种自适应融合策略,从文本和标签中提取特征。Chen等人(2021)将该问题视为语义匹配,并尝试BERT作为文本编码器。Wang等人(2021a)提出了HTC的认知结构学习模型。与其他工作类似,它们分别建模文本和标签。
对比学习
对比学习是计算机视觉(CV)中提出的一种弱监督表示学习方法。MoCo(He等人,2020)和SimCLR(Chen等人,2020b)等著作在多个CV数据集上弥合了自我监督学习和监督学习之间的差距。将对比学习应用于NLP的一个关键组成部分是如何构建正对(Pan等人,2021年)。数据增强技术如反向翻译(Fang et al., 2020)、词或跨度排列(Wu et al., 2020)和随机掩蔽(孟et al., 2021)可以生成具有相似含义的数据对。Gao等人(2021)在相同的数据上使用不同的dropout mask来生成正对。Kim等人(2021)通过BERT的固定副本使用BERT表示。这些方法不依赖于下游任务,而一些研究人员利用监督信息来更好地进行文本分类。Wang等人(2021b)构建了积极和消极对,特别是通过替换词来进行情感分类。Pan等人(2021年)提出通过FGSM (Goodfellow等人,2014)将基于transformer的编码器正则化,用于文本分类任务,这是一种基于梯度的对抗攻击方法。虽然以上方法都是为了分类而设计的,但正样本的构建几乎不依赖于它们的类别,忽略了不同标签之间的联系和多样性。对于HTC,分类层次模型之间的标签之间的关系,我们相信这可以帮助正样本生成。
Problem Define
给定一个输入,HTC预测标签集合(label set)的一个子集,其中是输入序列的长度,是集合的大小。
候选标签是预先定义的,并被组织为一个DAG(有向无环图),其中结点集合是标签,边集合是他们的层次结构。
为了简单起见,不区分标签和它在层次结构中的节点,因此既是标签又是节点。因为HTC的非根标签有且只有一个父标签,所以分类层次结构可以转换为树状层次结构。子集对应中的一条或多条路径:对于任意非根标签, 的一个父节点(label)在子集中。
Methodology
详细介绍HGCLR(分层引导学习)
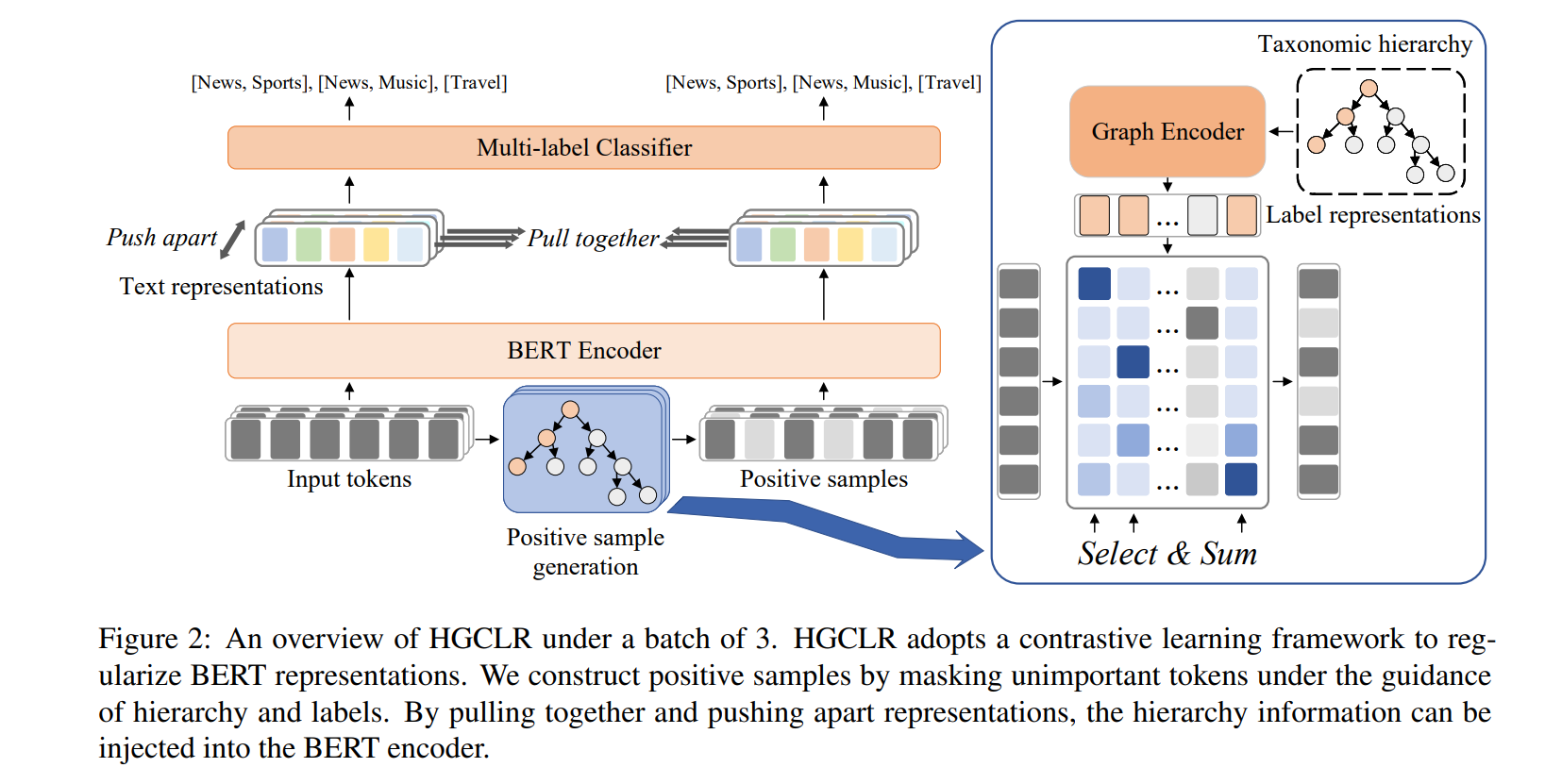
Text Encoder
本方法需要一个强大的文本编码器来进行层次注入,因此选择BERT作为文本编码器。给定一个输入token序列:
其中[CLS]和[SEP]是两个特殊的标记,表示序列的开始和结束,作为输入将被送入BERT。 为了方便起见,我们将序列的长度表示为。
文本编码器输出每个标记的隐藏表示:
其中,为隐藏层大小。
使用第一个标记([CLS])的隐藏状态来表示整个序列
Graph Encoder
使用定制的Graphormer对标签层次结构进行建模。 Graphormer在Transformer层的基础上,通过spatial encoding和edge encoding对图进行建模,因此它可以利用图领域中最强大的序列模型网络。我们将节点的原始特征组织为标签嵌入与其名称嵌入之和:
标签嵌入是一种可学习的嵌入,它以一个标签作为输入,输出一个大小为的向量。名称嵌入利用了标签的名称,假设它包含了整个类的丰富信息。使用标签的BERT嵌入的平均值作为它的名称嵌入,它的大小也为。与之前的工作不同,我们在文本和标签之间共享嵌入权重,使标签特性更具指导性。将所有节点特征堆叠作为矩阵,然后使用一个标准的self attention layer进行特征迁移。
为了利用结构信息,spatial encoding和edge encoding在self attention layer修改Query-Key矩阵:
其中,,等式中的第一项为标准的scale dot attention,其中query和key被和所投影。为edge encoding,表示两个结点和之间的举例。
由于在我们的问题中图是一个树,对于节点和,有且只有一条路径,则表示两个节点之间的边信息,是每个边的可学习权值。是spatial encoding,它衡量两个节点之间的连通性。它是一个可学习的标量,以为索引。
将图中涉及到的注意力权重矩阵,再用Softmax与值矩阵相乘,再用残差链接和layer norm计算self-attention。
下一步使用作为label feature。我们使用的Graphormer是self attention layer的变体,更多关于Graphormer完整结构的细节,可以参考原文。
Positive Sample Generation
如前所述,正样本生成的目标是在保留标签的同时保留一部分标记。给定一个的符号序列,定义BERT的符号嵌入为:
首先计算token embedding和标签特征之间的scale-dot attention,以确定token在标签上的重要性。
query和key分别是token嵌入和标签特征,,是两个权重矩阵。因此,对于某个,它属于标签的概率可以用Softmax函数归一化。
接下来,给定一个标签,我们可以从该分布中抽取出关键的token,并形成一个正样本。为了使采样可微,将Softmax函数替换为Gumbel-Softmax(Jang et al., 2016)来模拟采样操作:
一个token可以影响多个标签,因此在这一步中,没有将概率离散为一个one-hot向量。相反,我们为正例保留token,如果它们被采样的概率超过某个阈值,,这也可以控制要重新训练的token的比例。对于多标签分类,我们将所有ground-truth标签的概率相加,得到一个token 关于其ground-truth标签集y的概率为:
最终,正样本被构建为
其中0是一个特殊的token,它嵌入全部为0,以便关键的token可以保持它们的位置。选择操作是不可微分的,因此我们以不同的方式实现它,以确保整个模型可以进行端到端训练。
正例样本被送入与原始样本相同的BERT:
并在分类之前获得一个序列表示,其中包含第一个标记。我们假设正样本应该保留标签,因此我们以正样本的分类损失作为图编码器和正样本生成的指导。
Contrastive Learning Module
直观地说,给定一对token序列及其对应的正符号序列,它们的句子级编码表示应该尽可能地相似。同时,不属于同一对的例子应该在表示空间中离得更远。
具体来说,使用一批N个隐藏状态的positive pairs $(h_{i},\hat{h_{i}}),我们在它们之上添加一个非线性层:
其中,,对于每个样本,有个nagative pairs,即该批中剩余的所有样本都是负样本。
因此,对于一批个样例,我们计算的NT-Xent损失(Chen et al., 2020b)为:
其中为余弦相似度函数,为,是一个匹配函数:
是一个超参数。
总对比损失是所有样本的平均损失:
Classification and Objective Function
根据之前的工作(Zhou et al., 2020),将多标签分类的层次结构扁平化。将隐藏的特征输入线性层,并使用sigmoid函数计算概率。标签上出现文本的概率为:
其中,,是权重和偏置。对于多标签分类,使用binary cross-entropy 损失函数作为文本关于标签的损失。
其中为ground truth,用代替,所构造正例的分类损失可以用上式和公式相似地计算。
最终的损失函数是原始数据的分类损失、构造正样本的分类损失和对比学习损失的组合:
其中是控制对比损失的超参数。
在测试过程中,我们只使用文本编码器进行分类,模型退化为带分类头的BERT编码器。