Hierarchy-aware Label Semantics Matching Network for Hierarchical Text Classification
论文名称
Hierarchy-aware Label Semantics Matching Network for Hierarchical Text Classification
会议: ACL2021
Abstract
由于标签层次结构复杂,层次化的文本分类是一项重要而具有挑战性的任务。现有的方法忽略了文本和标签之间的语义关系,所以它们不能充分利用层次信息。为此,我们将文本-标签语义关系表述为一个语义匹配问题,从而提出了一个层次感知的标签语义匹配网络(HiMatch)。首先,我们将文本语义和标签语义投影到一个联合嵌入空间。然后,我们引入联合嵌入损失和匹配学习损失来模拟文本语义和标签语义之间的匹配关系。我们的模型以分层感知的方式捕捉到粗粒度标签和细粒度标签之间的文本-标签语义匹配关系。在各种基准数据集上的实验结果证明,我们的模型取得了最先进的结果。
Introduction
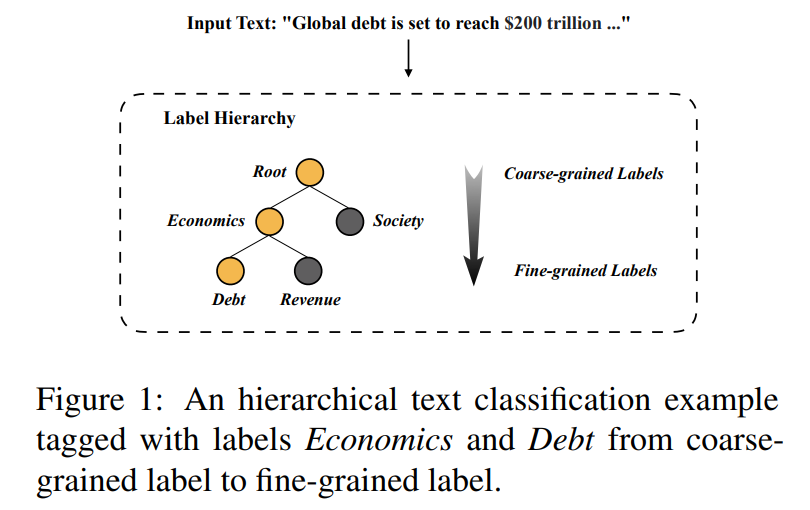
层次文本分类(HTC)广泛用于自然语言处理(NLP),如新闻分类(Lewis等人,2004)和科学论文分类(Kowsari等人,2017)。HTC是一个特殊的多标签文本分类问题,它引入了层次结构来组织标签结构。如图1所示,HTC模型在给定的标签层次中预测多个标签,一般以自上而下的方式构建一个或多个从粗粒度标签到细粒度标签的路径(Aixin Sun and E-Peng Lim, 2001)。一般来说,细粒度的标签是描述输入文本的最合适的标签。粗粒度的标签一般是粗粒度或细粒度标签的父节点,表达的是一个更普遍的概念。HTC的关键挑战是对大规模的、不平衡的、结构化的标签层次进行建模(Mao等人,2019)。
在HTC的现有工作中,引入了各种方法,以整体的方式使用层次信息。为了捕捉整体的标签相关特征,一些研究者提出了一个层次感知的全局模型,通过图卷积网络(GCN)和TreeLSTM来利用标签依赖的先验概率(Zhou等人,2020)。一些研究者还引入了更多的标签相关特征,如标签语义相似度和标签共现度(Lu等人,2020)。他们遵循传统的方式,将HTC转化为每个标签的多个二进制分类器(Furnkranz等人,2008)。然而,他们忽略了文本语义和标签语义之间的互动(Furnkranz等人,2008;Wang等人,2019),这对分类非常有用(Chen 等人,2020)。因此,他们的模型可能不足以对复杂的标签依赖关系进行建模并提供可比的文本-标签分类分数(Wang等人,2019)。
对文本语义和标签语义之间的互动进行建模的一个自然策略是通过标签注意力(Xiao等人,2019)或自编码器(Yeh等人,2017)引入文本-标签联合嵌入。基于标签注意力的方法采用了自注意机制来识别标签的特定信息(Xiao等人,2019)。基于自编码器的方法将典型的相关编码器(Yeh等人,2017年)扩展到基于排名的自动编码器架构,以产生可比较的文本-标签分数(Wang等人,2019年)。然而,这些方法假设所有的标签都是独立的,没有充分考虑粗粒度的标签和细粒度的标签之间的相关性,这不能简单地转移到HTC模型中(Zhou等人,2020)。
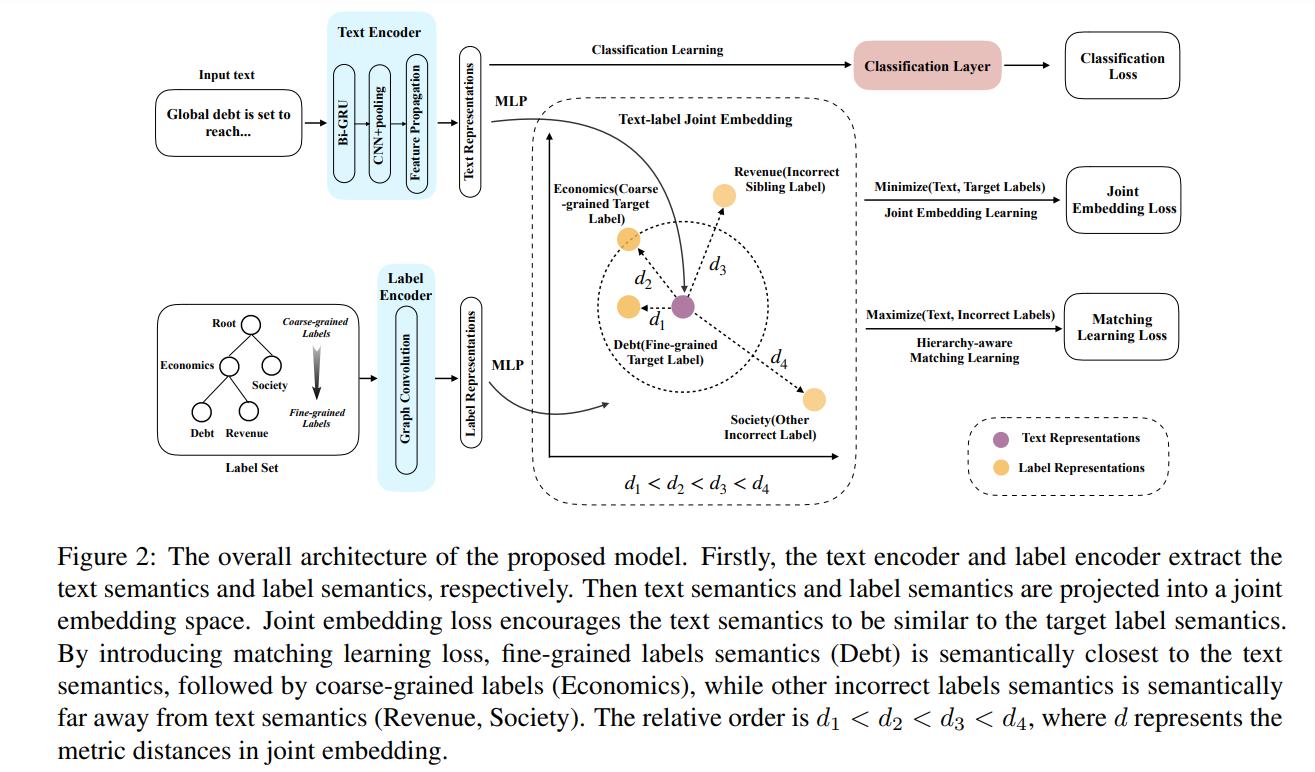
本文做出的改进: 将文本和标签之间的交互作用表述为一个语义匹配问题,并提出一个层次感知的标签语义匹配网络(HiMatch)。其主要思想是,文本表征应与目标标签表征(尤其是细粒度的标签)在语义上相似,而它们应在语义上远离错误的标签表征。具体流程如下:
- 首先,采用一个文本编码器和一个标签编码器(如图2所示)来分别提取文本语义和标签语义。
- 其次,受学习共同嵌入方法的启发(Wang等人,2019),我们将文本语义和标签语义都投射到文本-标签联合嵌入空间中,其中文本和标签之间的相关性得到了利用。在这个联合嵌入空间中,我们在文本语义和目标标签语义之间引入了一个联合嵌入损失,以学习文本-标签联合嵌入。之后,我们应用匹配学习损失,以分层感知的方式捕捉文本-标签匹配关系。这样一来,细粒度的标签在语义上最接近文本语义,其次是粗粒度的标签,而不正确的标签在语义上应该远离文本语义。因此,我们提出了一种分层感知的匹配学习方法,通过对语义距离的不同惩罚幅度来捕捉不同的匹配关系。
- 最后,采用由联合嵌入损失和匹配学习损失指导的文本表征来进行分层文本分类。
提示
本文主要贡献:
- 通过考虑文本-标签语义匹配关系,首次将HTC表述为一个语义匹配问题,而不仅仅是多个二元分类任务。
- 提出了一个层次感知的标签语义匹配网络(HiMatch),其中我们引入了一个联合嵌入损失和一个匹配学习损失,以层次感知的方式学习文本-标签语义匹配关系。
- 在各种数据集上进行的广泛实验(有/无BERT)表明,我们的模型取得了最先进的结果。
Related Work
Hierarchical Text Classification
分层文本分类是一个特殊的多标签文本分类问题,其中分类结果被分配到一个或多个分类层次的节点上。现有的最先进的方法主要是在全局视图中对层次结构约束进行编码,如有向图和树结构。Zhou等人(2020)提出了一个层次感知的全局模型,以利用标签依赖性的先验概率。Lu等人(2020)引入了三种标签知识图,即分类图、语义相似性图和共现图,以有利于分层文本分类。他们将分层文本分类视为多个二元分类任务(Furnkranz等人,2008)。其局限性在于,这些模型没有考虑标签语义和文本语义的相互作用。因此,他们未能捕捉到复杂的标签依赖关系,不能提供可比较的文本-标签分类分数(Wang等人,2019),导致性能受限(Chen等人,2020)。因此,利用文本和标签语义之间的关系是至关重要的,并帮助模型以可比较和分层感知的方式区分目标标签和不正确标签。在这项工作中,我们在文本和标签的联合嵌入中进行匹配学习来解决这些问题。
Exploit Joint Embedding of Text and Label
为了确定文本和标签之间的相关性,研究人员提出了各种方法来利用文本-标签联合嵌入,如(Xiao等人,2019)和自动编码器(Yeh等人,2017)。在多标签文本分类领域,Xiao等人(2019)提出了一个标签特定注意力网络(LSAN),通过标签语义和文档语义来学习文本-标签联合嵌入。Wang等人(2019)将vanilla 典型相关自编码器(Yeh等人,2017)扩展到基于排名的自动编码器架构,以产生可比的标签分数。然而,他们没有充分考虑标签语义和细粒度标签、粗粒度标签和不正确标签之间的整体标签关联性。此外,由于层次结构的限制,我们不能简单地将这些多标签分类方法转移到HTC上(Zhou等人,2020)。
Proposed Method
Text Encoder
在HTC任务中,给定输入序列,模型将预测标签,其中是词的数量,是标签集的数量。概率高于固定阈值的标签将被视为预测结果。标记嵌入序列首先被送入双向GRU层以提取上下文特征。然后,采用具有top-k、max-pooling的CNN层来生成关键n-gram特征,其中表示CNN层的输出尺寸。
继之前的工作(Zhou等人,2020),我们进一步引入了一个层次感知的文本特征传播模块来编码标签层次信息。我们将层次结构标签结构定义为一个有向图,其中表示层次结构节点的集合。是由自上而下的层次结构路径建立的,代表从父节点到子节点的先验统计概率。\mathop{E}\limits ^{\rightarrow}是由自下而上的层次结构路径建立的,代表从子节点到父节点的连接关系。图邻接矩阵和的特征大小为,其中为标签集的数量。文本特征传播模块首先通过线性变换将文本特征投射到节点输入,其中代表文本特征的层次结构节点维度。然后采用图卷积网络(GCN)将文本语义与先验层次信息和明确地结合起来。
其中,为激活函数ReLU,是GCN的权重矩阵,是先验层次结构路径感知的文本表示。
Label Encoder
在HTC任务中,层次化的标签结构可以被视为一个有向图,其中表示具有标签表示的层次结构节点的集合。标签编码器中的图G与文本编码器中的图有着相同的结构。
鉴于总的标签集作为输入,我们首先通过预训练的标签嵌入的平均化来创建标签嵌入。然后,GCN可以作为标签编码器使用。
其中,为激活函数ReLU,是GCN的权重矩阵,是先验层次结构路径感知的文本表示。必须注意的是,标签编码器的权重矩阵和输入表示法与文本编码器的不同。
Label Semantics Matching
Joint Embedding Learning
这一节将介绍学习文本-标签联合嵌入和层级匹配关系的方法。对于联合嵌入的学习,首先,我们将文本语义和标签语义投射到一个共同的潜在空间,如下所示。
其中和是独立的两层前馈神经网络。分别代表联合嵌入空间中的文本语义和标签语义,表示联合嵌入的维度。
为了使潜空间中两个独立的语义表征保持一致,我们采用了文本语义和目标标签语义之间的平均平方损失。
其中是目标标签集。旨在最小化输入文本和目标标签之间的共同嵌入损失。
Hierarchy-aware Matching Learning
基于文本-标签联合嵌入损失,该模型只捕捉到文本语义和目标标签语义之间的相关性,而不同粒度的标签之间的相关性被忽略。
在HTC任务中,预计文本语义和细粒度标签之间的匹配关系应该是最接近的,其次是粗粒度标签。文本语义和不正确的标签语义不应该有关系。
鉴于此,我们提出了一个层次感知的匹配损失,以纳入文本语义和不同标签语义之间的相关性。旨在惩罚文本语义和不正确的标签语义之间的小的语义距离,其幅度为。
其中代表目标标签语义,代表不正确标签语义。我们使用L2归一化的欧几里得距离作为度量,是基于边际的三联体损失的边际常数。我们将每个标签对之间所有损失的平均值作为边际损失。
Hierarchy-aware Margin
由于HTC任务中的大型标签集,计算每个标签的匹配损失是很耗时的。因此,我们提出了层次感知的抽样来缓解这个问题。具体来说,我们对所有的父标签(粗粒度标签)、一个同级标签和每个细粒度标签的一个随机不正确标签进行抽样,以获得其负标签集。为不同的标签对分配相同的margin也是不合理的,因为在一个大的结构化标签层次中,标签语义的相似性是相当不同的。我们的基本想法是,如果两个标签在层次结构中比较接近,那么语义关系应该比较接近。首先,文本语义应该与细粒度的标签最匹配,这在联合嵌入学习中得到了利用。然后,我们将语义距离最小的一对()视为正例对,将其他文本标签匹配对视为负例对。如图3所示,与正对相比,文本和粗粒度目标标签之间的语义匹配距离()应该更大。不正确的兄弟标签与目标标签有一定的语义关系。因此,文本与细粒度标签的不正确同级标签之间的语义匹配距离()应该进一步加大,而文本与其他不正确标签之间的语义匹配距离()应该是最大。我们引入层次感知的惩罚margins:、、、来模拟这种可比关系。如果我们预期语义匹配距离较小,则惩罚margin较小。我们忽略了,因为文本语义和细粒度标签之间的匹配关系在联合嵌入学习中被利用。、、是与文本语义和细粒度标签语义之间的匹配关系相比的惩罚margins。我们引入两个超参数、来衡量的不同匹配关系。
其中,所提出的损失以分层的方式捕捉目标标签和不正确标签之间的相对语义相似度排名。
Classification Learning and Objective Function
我们发现,如果我们直接在文本-标签联合嵌入中进行分类学习,更容易出现过拟合的情况。因此,我们使用由联合嵌入损失和匹配学习损失指导的文本语义表示来进行分类学习。被送入全连接层,得到用于预测的标签概率。
总体目标函数包括交叉熵类别损失、联合嵌入损失和层次感知匹配损失:
其中,和分别是ground truth标签和输出概率。和是平衡联合嵌入损失和匹配学习损失的超参数。在训练过程中,我们通过梯度下降法使上述函数最小。