Hierarchy-Aware Global Model for Hierarchical Text Classification
论文名称
Hierarchy-Aware Global Model for Hierarchical Text Classification
会议:ACL2020
Abstract
分层文本分类是具有分类层次的多标签文本分类的一项重要而富有挑战性的子任务。
现有方法的问题:
- 在全局视图下对分层标签结构进行建模时存在困难。
- 它们不能充分利用文本特征空间和标签空间之间的相互作用。
本文改进:
- 用有向图的形式表达层次结构,并引入层次感知结构编码器来建模标签依赖。
- 在层次编码器的基础上,提出了一种新颖的端到端层次感知全局模型(HiAGM)。多标签attention变体(HiAGM-LA)通过层次编码器学习层次感知的标签嵌入,并对标签感知的文本特征进行归纳融合。
- 提出了一种文本特征传播模型(HiAGM-TP)作为演绎变量,直接将文本特征提供给层次编码器。与之前的工作相比,HiAGM-LA和HiAGMTP在三个基准数据集上都实现了显著和一致的改进。
Introduction
本文涉及的相关任务:
- 分层文本分类(HTC):与一般的文本分类,不同之处在于label具有层次结构。
- 多标签文本分类(MLC):一次性地根据给定输入预测多个二分类目标。
文本分类被广泛应用于自然语言处理(NLP)应用中,如情感分析(Pang和Lee, 2007)、信息检索(Liu等,2015)和文档分类(Yang等,2016)。
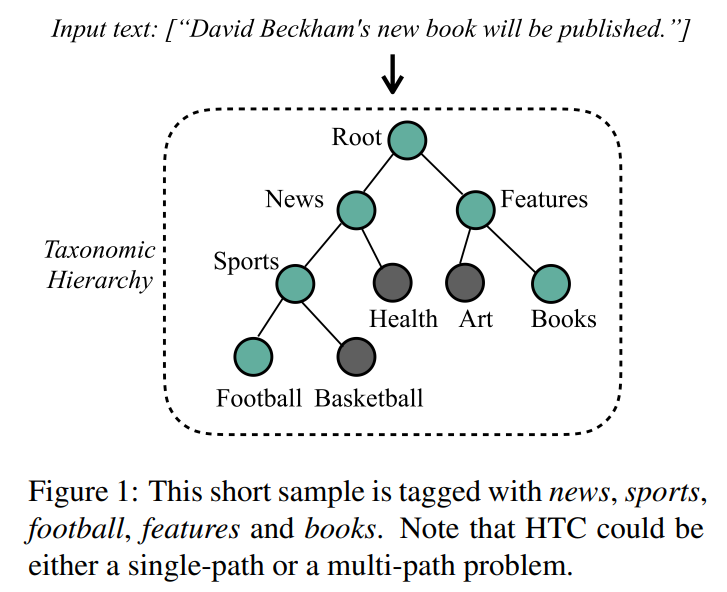
分层文本分类(HTC)是一个特殊的多标签文本分类(MLC)问题,其中分类结果对应于分类法层次结构的一个或多个节点。分类层次结构通常建模为树或有向无环图,如图所示。
HTC现有的方法可以分为两类,局部方法和全局方法。:
- 局部方法: 倾向于构建多个分类模型,然后以自顶向下的方式遍历层次结构。之前的局部研究提出通过向父节点学习来克服子节点上的数据不平衡。但是,这些模型含有大量的参数,由于缺乏整体的结构信息,容易导致暴露偏差。
- 全局方法: 将HTC问题视为一个平面MLC问题,并对所有类使用一个分类器。最近的全局方法引入了各种策略来利用自上而下路径的结构信息,如递归正则化、强化学习和元学习。目前还没有对标签相关特征的整体标签结构进行编码的全局方法。此外,这些方法仍然以一种浅层的方式利用层次结构,从而忽略在我们的工作中已经证明更有成效的细粒度标签相关信息。
本文做出的改进:
- 将层次结构表述为一个有向图,并利用标签依赖的先验概率来聚合节点信息。
- 提出了一种基于层次感知的全局模型(HiAGM),利用标签结构特征增强文本信息。它包括用于提取文本信息的传统文本编码器和用于分层标签关系建模的分层感知结构编码器。层次感知结构编码器可以是TreeLSTM,也可以是集成了层次先验知识的层次GCN。此外,这两种结构编码器是双向计算的,允许它们以自顶向下和自底向上的方式捕获标签相关信息。因此,HiAGM比以往的自顶向下模型更加健壮,能够缓解暴露偏差和数据不平衡造成的问题。
为了聚合文本特征和标签结构特征,提出了两种HiAGM变体:
- 多标签注意力模型HiAGM-LA
- 文本特征传播模型HiAGM-TP
相同之处: 这两个变体都是基于结构编码器提取层次感知的文本特征。
不同之处: HiAGM-LA以归纳的方式提取标签文本特征,而HiAGM-TP以演绎的方式生成混合信息。HiAGM-LA更新跨整体层次结构嵌入的标签,然后使用节点输出作为感知层次结构的标签表示。最后,对标签感知文本特征进行多标签注意。另一方面,HiAGM-TP在串行数据流中直接利用文本特性作为结构编码器的输入。因此,它在整个层次结构中传播文本信息。整个层次结构中每个节点的隐藏状态表示特定于类的文本信息。
paper的贡献如下:
- 利用先验的层次结构知识,我们采用自顶向下和自底向上的典型结构编码器对标签依赖关系进行建模,这在分层文本分类中还没有研究过。
- 提出了一种新颖的端到端层次感知全局模型(HiAGM)。我们进一步提出了两种基于标签的文本特征的变体,一个层次感知的多标签注意力模型(HiAGM-LA)和一个层次感知的文本特征传播模型(HiAGM-TP)。
- 我们的经验证明,HiAGM的两种变体在使用不同的结构编码器时,在各种数据集上都实现了一致的改进。在RCV1-V2上,我们最好的模型比最先进的模型的MacroF1和Micro-F1分别高出3.25%和0.66%。
- 发布了Web-of-Science和NYTimes的代码和实验片段。
Related Work
现有的HTC分为局部和全局方法。
- 局部方法可细分为每个节点的局部分类器(LCN)(Banerjee等人,2019年)、每个父节点的局部分类器(LCPN)(Dumais和Chen,2000年)、父节点(LCPN)(Dumais和Chen,2000)和每层本地分类器(LCL)(Shimura et al, 2018;Wehrmann等人,2018;Kowsari等人,2017)。Banerjee等人(2019),为子模型转移父模型的参数,作为LCN。Wehrmann等人(2018)通过LCL和全局优化的混合方法缓解了暴露偏差问题。LCL和全局优化的混合方案来缓解暴露偏差问题。Peng等人(2018)将层次结构分解为子图,并对n-gram tokens使用Text-GCN。
- 全局方法利用层次信息改进了平面MLC模型。Cai和Hofmann(2004)通过分解将SVM修改为Hierarchical-SVM。Gopal和Yang(2013)提出了相邻类之间参数的简单递归正则化。在全局模型中也采用了深度学习架构,如序列到序列(Yang等人,2018)、元学习(Wu等人,2019)、强化学习(Mao等人,2019)和胶囊网络(Peng等人,2019)。这些模型主要集中在基于分层路径的约束来改进解码器。相比之下,我们提出了一个有效的层次感知的全局模型HiAGM,它根据事先的层次信息,用层次编码器提取关于标签的文本特征。
此外,Mullenbach等人(2018)在MLC中引入了注意力机制,用于ICD编码。Rios和Kavuluru(2018)通过基本的GraphCNN训练标签表示,并通过残差连接进行多标签注意力。AttentionXML(You等人,2019)通过标签集群将MLC转换为多标签注意力LCL模型。Huang等人(2019)用每层的标签注意力改进了HMCN(Wehrmann等人,2018)。然而,我们的HiAGM-LA在一个单一的模型中采用了多标签注意力,并有一个简化的结构编码器,降低了计算的复杂性。
最近在语义分析(Chen等人,2017b)、语义角色标记(He等人,2018)和机器翻译(Chen等人,2017a)方面的工作表明,语法编码器的句子表示有了改进,例如基于树的RNN(Tai等人,2015;Chen等人,2017a)和GraphCNN(Marcheggiani和Titov,2017)等。我们以自上而下和自下而上的方式为HTC修改这些结构编码器,使其具有细粒度的先验知识。
Problem Define
分层文本分类(HTC)是文本分类的一个子任务,用一个预定义的分类层次来组织标签空间。该层次结构是根据整体语料库预定义的。该层次结构根据类别关系将标签子集分组。分类层次结构主要包含树状结构和有向无环图(DAG)结构。请注意,DAG可以通过区分每个标签节点为单路径节点而转化为树状结构。因此,分类层次结构可以简化为树状结构。
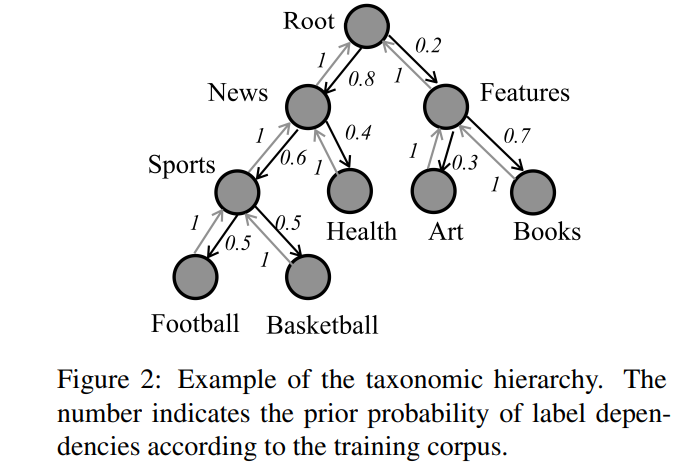
我们将分类层次结构表述为一个有向图,其中V指的是标签节点的集合,C表示标签节点的数量。是自上而下的层次结构路径,是自下而上的层次结构路径,形式上,我们将HTC定义为有一个文本对象的序列和一串对齐的监督标签集。
如图1所示,每个样本都对应于一个包括多个类的标签集。那些对应的类属于层次结构中的一个或多个子路径。注意,在与子节点有关的条件下,样本属于父节点。
Hierarchy-Aware Global Model
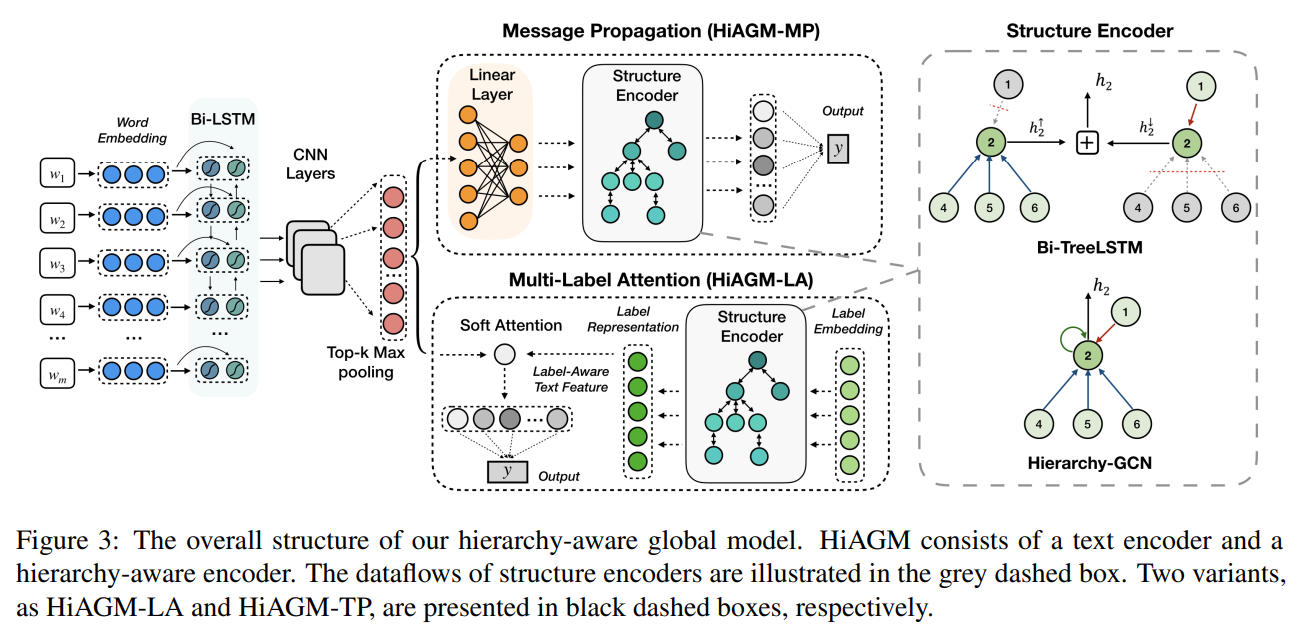
如Figure 3所示,我们提出了一个HierarchyAware Global Model(HiAGM),它利用了细粒度的层次信息,然后聚合了标签相关的文本特征。HiAGM包括一个用于文本信息的传统文本编码器和一个用于分层标签相关特征的层次感知结构编码器。
我们提出了两个用于混合信息聚合的HiAGM变体,一个是多标签注意力模型(HiAGM-LA),一个是文本特征传播模型(HiAGM-TP)。HiAGM-LA通过结构编码器更新标签表示,并通过多标签注意力机制生成标签感知的文本特征。HiAGM-TP在整个整体层次结构中传播文本表征,从而获得具有标签相关性的文本特征,并与标签相关性相融合。
Prior Hierarchy Information
分类层次描述了标签之间的层次关系。HTC的主要瓶颈是如何充分利用这一既定结构。以前的研究在基于流水线框架、层次模型或标签分配模型的静态方法中直接利用这种层次路径。相比之下,基于贝叶斯统计推理,HiAGM利用了关于预定的层次结构和语料库的标签相关性的先验知识。我们利用标签相关性的先验概率作为先验层次结构知识。
假设在父节点和子节点之间有一条层次结构路径。这个边缘特征由先验概率和表示为。
其中表示的出现次数,是在发生的情况下的条件概率。是同时发生的概率。指的是训练子集中的数量。请注意,层次结构确保给定发生。我们对子节点的先验概率进行重新划分和归一化,使之总和为1。
ps:其实应该就是算给定父节点每个儿子结点对应的概率。
Hierarchy-Aware Structure Encoder
树LSTM和图卷积神经网络(GCN)被广泛用作NLP中聚合节点信息的结构编码器(Tai等人,2015;Chen等人,2017a;He等人,2018;Rios和Kavuluru, 2018)。如Figure 3所示,HiAGM基于层次感知结构编码器对细粒度的层次信息进行建模。基于先前的层次信息,我们改进了有向层次图的典型结构编码器。具体来说,自上而下的数据流采用先验层次信息为,而自下而上的数据流采用。
Bidirectional Tree-LSTM
树LSTM可以作为我们的结构编码器使用。Tree-LSTM的实现与语法编码器相似(Tai等人,2015;Zhang等人,2016;Li等人,2018)。预定义的层次结构对所有的样本都是相同的,这使得这个递归计算模块可以采用小批量的训练方法。节点转换如下:
其中,和分别表示结点隐藏状态和记忆单元状态。
为了推导标签的相关性,HiAGM采用了一个双向的Tree-LSTM,由一个child-sum和一个top-down模块融合而成:
其中和分别以自下而上和自上而下的方式计算为。表示隐藏状态的连接。节点的最终隐藏状态是分层的节点表示。
Hierarchy-GCN
GCN(Kipf和Welling,2017)被提出来,以增强基于局部图结构信息的节点表示。一些NLP研究根据句法结构和词的相关性改进了Text-GCNs,以获得丰富的词表示(Marcheggiani and Titov, 2017; Vashishth et al., 2019; Yao et al., 2019; Peng et al., 2018)。我们为层次结构引入了一个简单的层次结构GCN, 从而获得我们前面提到的细粒度的层次结构信息。
Hierarchy-GCN将数据流聚集在自上而下、自下而上和自循环的边内。在层次图中,每条有向边代表一个成对的标签相关特征。因此,这些数据流应该用edge-wise的线性变换进行节点变换。然而,edge-wise变换应导致过度参数化的edge-wise的权重矩阵。我们的Hierarchy-GCN用一个加权相邻矩阵简化了这种转换。这个加权相邻矩阵代表了层次性的先验概率。形式上,Hierarchy-GCN根据节点的相关邻域来编码节点的隐藏状态,即:
其中,,。表示从节点到节点的层次方向,包括自上而下、自下而上和自环边。注意,表示层次概率,其中自环边采用,自上而下的边缘采用,自下而上的边采用。整体边缘特征矩阵表示有向层次图的加权相邻矩阵。最后,节点的输出隐藏状态表示其对应于层次结构信息的标签表示。
Hybrid Information Aggregation
以前的全局模型在原始文本信息的基础上对标签进行分类,并通过预定义的层次路径改善解码器。相比之下,我们为文本特征和标签相关性的相互作用构建了一个新颖的端到端层次感知全局模型(HiAGM)。它将传统的文本分类模型与层次结构编码器结合起来,从而获得标签导向的文本特征。HiAGM被扩展为两个变体,一个是用于归纳融合的并行模型(HiAGM-LA),一个是用于演绎融合的串行模型(HiAGM-TP)。
给定一个文档,标记嵌入的序列首先被送入双向GRU层以提取文本上下文特征。然后,使用多个CNN来生成n-gram特征。n-gram特征的串联被top-k和max-pooling层过滤以提取关键信息。最后,通过reshape,我们可以得到连续的文本表征,其中,表示CNN层的输出维度。指的是top-k和CNN的乘法。
Hierarchy-Aware Multi-Label Attention
HiAGM的第一个变体是基于多标签注意力提出的,称为HiAGM-LA。注意力机制通常被用作文本分类的记忆单元(Yang等人,2016;Du等人,2019)。最近的LCL研究(Huang等人,2019;You等人,2019)为每个层次构建了一个基于多标签注意力的模型,以避免在不同层次之间优化标签嵌入。
我们的HiAGM-LA与这些baseline相似,但将多标签注意力LCL模型简化为一个全局模型。基于我们的层次编码器,HiAGM-LA可以克服标签嵌入在不同层次上的收敛问题。 标签表征通过双向的层次信息得到增强。这种局部结构信息使得在一个模型中学习不同层次的标签特征是可行的。形式上,假设节点的可训练标签嵌入被随机初始化为。初始标签嵌入作为对齐标签节点的输入向量直接送入结构编码器。然后,输出的隐藏状态表示为层次感知的标签特征。 给定文本表示,HiAGM-LA计算出标签相关的注意力值为。
注意,表示第个文本特征向量对第个标签的信息量有多大。我们可以得到基于多标签注意力机制的归纳标签对齐的文本特征。然后将其送入分类器进行预测。此外,我们可以直接使用层次结构编码器的隐藏状态作为预训练的标签表征,这样HiAGM-LA在推理过程中就可以更加轻巧了。
Hierarchical text feature propagation
图神经网络能够进行信息传递(Gilmer等人,2017;Duvenaud等人,2015),同时学习局部节点的相关性和整体图结构。为了避免异质融合带来的噪音,第二种变体是基于演绎法获得标签式文本特征。它直接将文本特征作为节点输入,并通过层级感知结构编码器更新文本信息。这个变体主要进行文本特征的传播,称为HiAGM-TP。从形式上看,节点输入是由文本特征通过单一的线性变换reshape而成。
其中,可训练的权重矩阵将文本特征转换为节点输入.
鉴于预设的结构,每个样本都会在同一个整体分类层次中更新其文本信息。以小批量学习的方式,初始节点表示V被送入层次结构编码器。输出的隐藏状态h表示演绎层次意识的文本特征,作为最终分类器的输入。与HiAGM-LA相比,HiAGMTP的转换是在文本信息上进行的,没有标签嵌入的融合。因此,结构编码器在训练和推理程序中都会被激活,以便在层次结构中传递文本信息。它可以更容易地收敛,但其计算复杂度比HiAGM-LA略高。
Classification
我们通过将所有节点作为多标签分类的叶子节点来使层次结构扁平化,无论它是叶子节点还是内部节点。最后的层次感知特征被送入全连接层进行预测。HiAGM与递归正则相辅相成(Gopal and Yang, 2013),为最终全连接层的参数。对于多标签分类,HiAGM使用二分类交叉熵损失函数:,其中和分别为第i个样本的第j个标签的ground truth和sigmoid score.因此最终的损失函数为.
Conclusion
在本文中,我们提出了一个新颖的端到端层次感知的全局模型,它可以提取标签结构信息来聚合标签相关的文本特征。我们提出了一个双向的TreeLSTM和一个层次结构的GCN作为层次感知的结构编码器。此外,我们的框架被扩展为基于多标签注意力的并行变体和文本特征传播的串行变体。我们的方法在三个不同的数据集上取得了显著和一致的改进,特别是在低频标签上。具体来说,两种变体在RCV1-V2基准数据集上的表现都超过了最先进的模型。而我们最好的模型获得了63.35%的Macro-F1得分和83.96%的Micro-F1得分。