HTCInfoMax A Global Model for Hierarchical Text Classification via Information Maximization
论文名称
HTCInfoMax: A Global Model for Hierarchical Text Classification via Information Maximization
会议: NAACL 2021
Abstract
目前分层文本分类的SOTA模型HiAGM主要存在的限制:
- 它将每个文本样本与数据集中的所有标签相关联,其中包含不相关的信息。
- 没有考虑到结构编码器所学的标签表示的任何统计约束,而表示学习的约束在以前的工作中被证明是有帮助的。
提出HTCInfoMax,通过引入信息最大化来解决这些问题,其中包括两个模块:文本-标签互信息最大化和标签先验匹配。作用如下:
- 第一个模块可以明确地模拟每个文本样本与它的ground truth标签之间的相互作用,从而过滤掉不相关的信息。
- 第二个模块鼓励结构编码器学习具有所有标签所需特征的更好的表示,这可以更好地处理分层文本分类中的标签不平衡。
在两个基准数据集上的实验结果证明了所提出的HTCInfoMax的有效性。
Introduction
任务简介
分层文本分类(HTC)是多标签文本分类的一个特殊子任务(Li等人,2020)。几十年来,许多数据集被提出来研究HTC,如RCV1(Lewis等人,2004)和NYTimes(Sandhaus,2008),它们将一条新闻分为几个类别/标签。而每个数据集中的所有标签通常被组织成一棵树或一个有向无环图。因此,每个数据集中都有一个标签的分类层次结构。HTC的目标是预测一个给定文本在一个给定的标签层次中的多个标签。
现有的HTC的方法有两组:局部方法和全局方法。本地方法通常为每个标签/节点建立一个分类器(Banerjee等人,2019),或为每个父节点,或为标签层次结构的每一级建立分类器(Wehrmann等人,2018;Huang等人,2019;Chang等人,2020)。全局方法只是建立一个分类器来同时预测一个给定文本的多个标签。早期的全局方法忽略了标签的层次结构,并假设标签之间没有依赖性,这导致了平面模型,如(Johnson和Zhang,2015)。后来,越来越多的工作试图利用标签的分类层次来提高性能,采用了不同的策略,如递归正则Graph-CNN(Peng等人,2018)、强化学习(Mao等人,2019)、注意力胶囊网络(Peng等人,2019)、元学习(Wu等人,2019)和结构编码器(Zhou等人,2020)。许多基于注意力的模型也被提出来学习更精细的文本特征,用于文本分类任务,如(You等人,2019;Deng等人,2020)。在这些方法中,Zhou等人(2020)提出的HiAGM是HTC最先进的模型,它设计了一个结构编码器,整合了标签先验层次知识来学习标签表征,然后在结构编码器的基础上提出了一个有两个变体的模型HiAGM(一个是HiAGM-LA,另一个是HiAGMTP)来捕捉文本特征和标签表征之间的相互作用。然而,HiAGM也有一些局限性。首先,它对每个文本样本都使用相同的标签层次信息,无法区分与特定文本样本相关和不相关的标签。尽管HiAGM-LA可以通过软注意力权重隐含地将每个文本与它相应的标签联系起来,但仍然存在不相关和嘈杂的信息。其次,对于HiAGM-LA来说,由结构编码器生成的标签嵌入没有任何统计约束,而统计约束则是由结构编码器生成的。
为了解决HiAGM-LA的两个局限性,我们提出了HTCInfoMax,它在HiAGM-LA的基础上引入了信息最大化的两个新模块,即文本-标签互信息最大化和标签先验匹配。具体来说,第一个新模块通过最大化每个文本样本和其相应的标签之间的互信息来明确建立联系,从而可以过滤掉特定文本样本的不相关标签信息。标签先验匹配模块可以对每个标签的学习表示施加一些约束,迫使结构编码器对所有标签学习具有理想属性的更好表示,从而也提高了低频标签的表示质量,这有助于更好地处理标签不平衡问题。
提示
本文主要贡献为:
- 我们通过引入信息最大化,为HTC提出了一个新颖的全局模型HTCInfoMax,它包括两个模块:文本-标签互信息最大化和标签先验匹配。
- 这是第一项利用文本-标签相互信息最大化的HTC工作,它使每个文本都能以有效的方式捕获其相应的标签信息。
- 这是第一项为HTC引入标签先验匹配的工作,它鼓励结构编码器为所有标签学习所需的标签表示,这可以更好地处理HTC中固有的标签不平衡问题。
- 实验结果证明了我们提出的HTC模型的有效性。
- 我们发布了我们的代码。
Methodology
Our approach
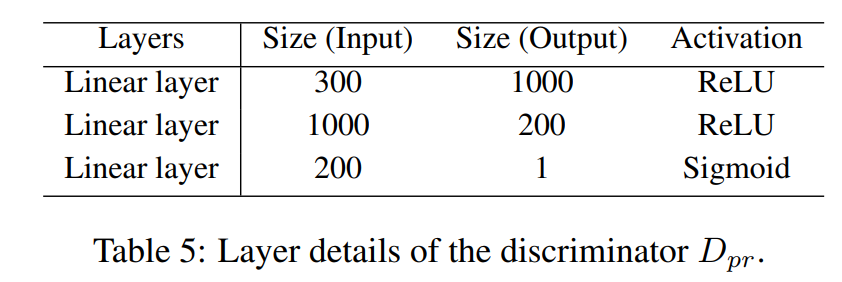
我们模型的整体架构如图1所示。HTCInfoMax的主要部分是虚线框内的 "信息最大化 "部分,它有两个新的模块:文本-标签互信息最大化和标签先验匹配,这将在下文中介绍。我们保持其余部分,如文本编码器、结构编码器和预测器与HiAGM-LA(Zhou等人,2020)中的相同。
Text-label mutual information estimation and maximization
良好的文本表示对于预测其对应的标签至关重要,因此将标签信息融合到文本特征中有助于提高预测性能。HiAGM-LA利用多标签注意力将每个样本的文本特征与所有标签信息隐含在一起,这可以在某种程度上帮助每个文本获得一些标签信息。然而,不相关的标签信息也会通过使用软注意力权重被注入文本特征中。因此,我们设计了一个文本-标签互信息最大化模块,以帮助去除每个文本的不相关标签信息,并帮助每个文本获取其相应的标签信息。这样一来,每个文本的学习表示就包含了有用的标签信息,有助于预测其标签。
为了实现文本-标签互信息最大化,我们首先在训练过程中为每个文本样本选择ground truth标签,然后应用判别器来估计文本和其标签之间的互信息,这也被称为负采样估计。让和分别表示文本编码器输出的文本特征分布和结构编码器产生的标签表示分布。文本和标签的联合分布被表示为。然后,正样本是文本和其对应的标签,表示为,换句话说,这些正样本是从文本和标签的联合分布中抽取的。对于负样本,我们将与同一批次的另一个文本样本配对,表示为,负样本可以被视为从文本和标签的边缘分布的乘积中抽取。正负样本都被送入判别器进行分类,并估计文本和标签之间的相互信息,如公式(1)所示。和分别代表判别器分配给正样本和负样本的概率分数。文本-标签相互信息最大化模块的目标是最大化,因此该模块的损失如公式(2)所示。
这个模块受到Deep InfoMax(DIM)(Hjelm等人,2019)的启发,DIM利用局部和全局的互信息最大化来帮助编码器学习图像的高级表示。本模块中判别器DMI的结构可以在附录A.1中找到。
Label prior matching
在HTC中存在一个固有的标签不平衡问题,因此,由于训练实例较少造成的欠拟合,模型对低频标签的学习标签嵌入并不理想。标签先验匹配对每个标签的学习表示施加了一些统计约束,这可以帮助结构编码器学习更好的标签表示,对所有的标签都有理想的特性。这也提高了低频标签的表示质量,有助于更好地处理标签不平衡的情况,提高Macro-F1得分。
为了实现标签先验匹配机制,我们使用了一种类似于对抗性自动编码器中对抗性训练的方法(Makhzani等人,2015),但没有生成器来强制学习的标签表示与先验分布相匹配。我们把先验表示为,把结构编码器学到的标签表示的分布表示为。具体来说,我们采用一个判别器网络来区分从先验中提取的表示/样本(即真实样本,表示为)和结构编码器产生的标签嵌入(即假样本,表示为y)。对于每个标签,我们利用来计算其相应的先验匹配损失,如公式(3)所示。
这种损失的目的是将一个标签的学习表示的分布P推向其先验分布Q。最终的标签先验匹配损失是所有标签损失的平均值,如公式(4)所示,N是标签的数量。
这个想法受到DIM的启发,DIM将图像的表征与先验相匹配,但与DIM不同的是,它通过对每个标签的表征施加约束,训练结构编码器学习所有标签的理想表征。
在标签先验匹配模块中,采用区间上的均匀分布作为标签先验分布。选择均匀分布的原因是它在DIM中作为生成图像表示的先验分布效果很好。而在分层文本分类的实验结果中,Macro-F1得分的提高进一步验证了使用均匀分布作为标签先验的适宜性。判别器的详细结构可以在附录A.2中找到。
Final loss of HTCInfoMax
采用损失权重估计器,通过使用学到的文本特征和所有标签的表示方法来学习文本-标签互信息损失和标签先验匹配损失的权重,如公式(5)所示,和都是可训练参数。
预测器的损失是传统的二进制交叉熵损失Lc(Zhou等人,2020)。那么HTCInfoMax的最终目标函数是所有三个损失的组合,如下所示:
Appendix: Architecture Details of Information Maximization
A.1 The structure of discriminator in text-label mutual information maximization module
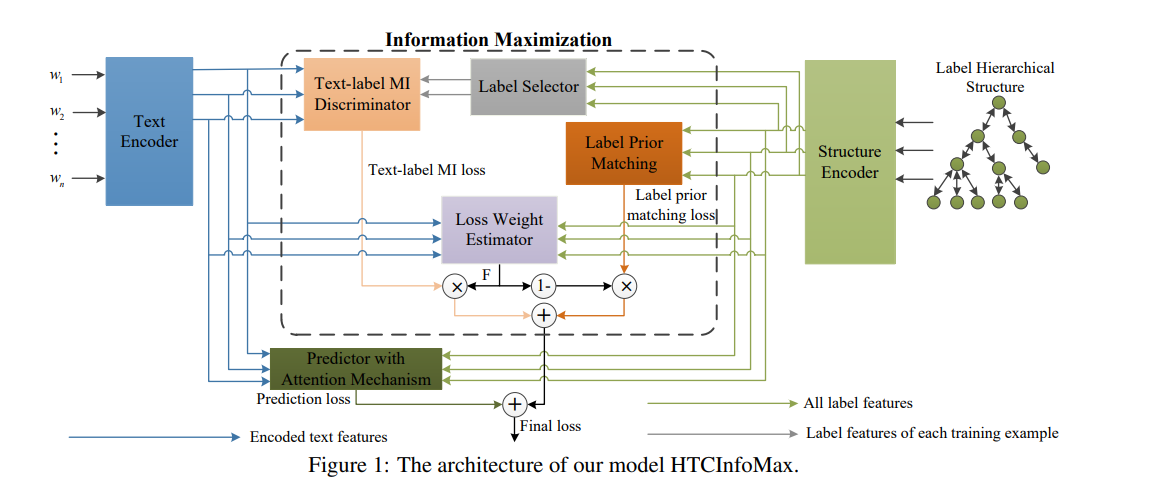
鉴别器由两个大小为3的kernel的一维卷积层和三个线性层组成。的结构如图2所示,所有层的细节见表4("-"表示相应层没有激活)。如图2所示,判别器将文本表示和标签表示作为输入对。文本表示首先被送入卷积层,然后标签表示与卷积层的输出相连接并被送入下面的线性层。最后的线性层为每对文本样本和相应的标签产生一个分数。
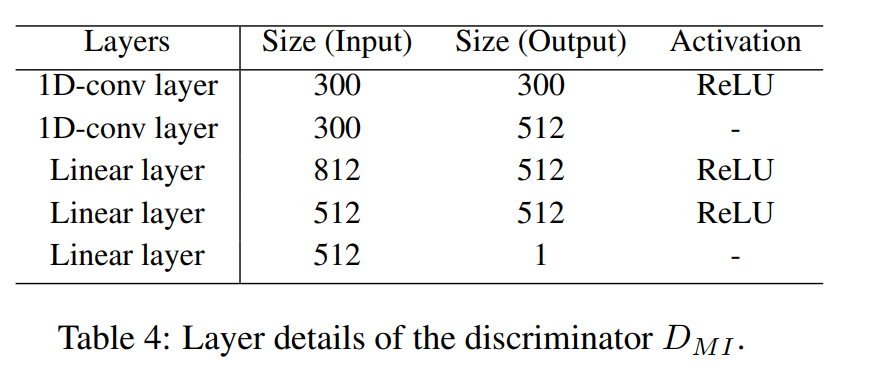

A.2 The structure of discriminator in label prior matching
标签先验匹配模块中的判别器由三个线性层组成。这些层的细节显示在表5中。该判别器将标签表示作为输入,并按照第2.1.2节所述,应用于每个标签计算其先验匹配损失。