一、RNN的几种基本的结构
1.1 结构一
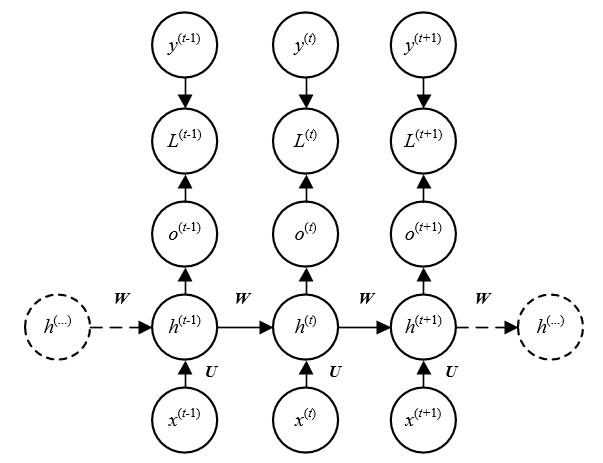
上述所示RNN的结构中,输入序列为X=(x0,x1,...,xl−1)。对于任意时刻t,ht由ht−1和xt共同决定。且目标时刻t对应于目标输出yt。这样的结构很适合时间序列类预测的任务,模型可以通过之前的信息ht−1和当前的输入xt来预测当前时刻的输出y^t。该结构最大的问题是时刻t的损失Lt与所有之前的状态ht−1,ht−2,...,h0都有关系。因此求ht时,要先求ht−1。在反向传播时,需要对每一个输入进行前向传播过程来计算网络的activation,而RNN的顺序计算,会导致难以并行化,导致训练较慢。
1.2 结构二
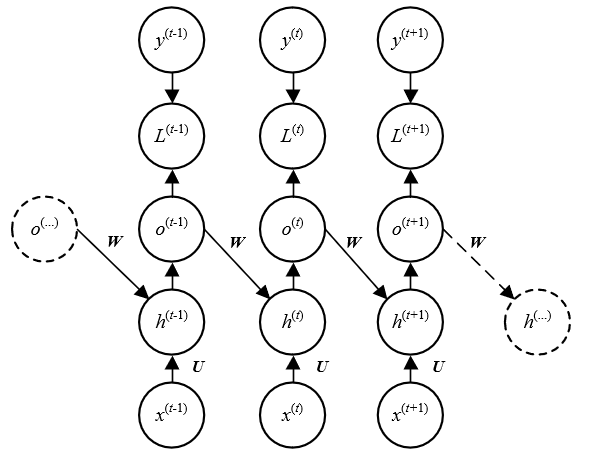
与结构一相比,这种结构取消了相邻时刻间状态h之间的连接,取而代之的是前一时刻的输出ot−1与当前时刻状态ht的连接,此时仍然是顺序计算,但o的维度通常小于h,因此训练参数可能减少。模型的缺点主要是yt中的信息远少于ht,因此模型对历史信息的学习能力不如结构一。
这种网络可以采用teacher forcing的方法来训练,ht的输入部分来自ot−1,而ot−1本身在训练过程中受yt−1的约束(ot−1要尽可能逼近yt−1),因此可以直接使用yt−1来代替ot−1作为ht的输入。
1.3 结构三
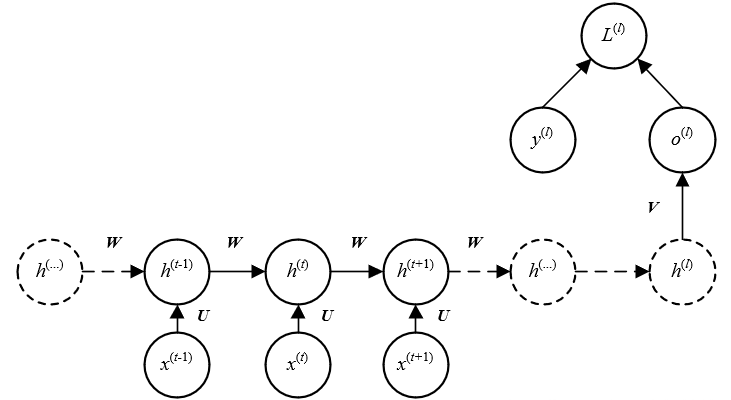
该结构的RNN仅在最后时刻l才会有输出ol。
二、前向传播
2.1 理论推导
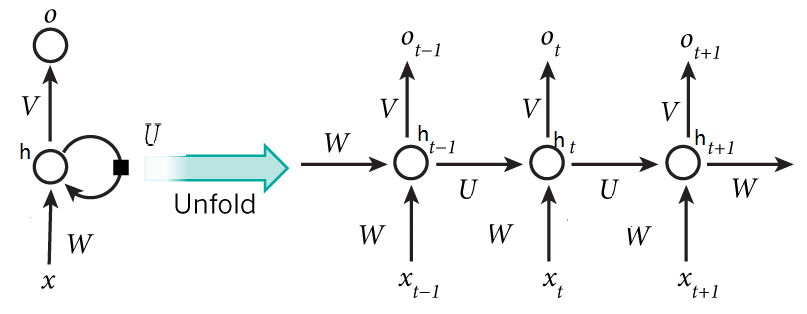
定义完全连接的循环神经网络,输入为xt,输出为yt。
ht=f(Uht−1+Wxt+b)
yt=Vht
提示
其中h为隐状态,f(⋅)为非线性激活函数,通常使用Logisitic函数或Tanh函数,U、W、b和V为网络参数。
xt∈RM表示时刻t网络的输入,ht∈RD表示隐藏层状态,U∈RD×D表示状态-状态权重矩阵,W∈RD×M表示状态-输入权重矩阵,b∈RD表示偏置向量。
若将每个时刻的状态都看作前馈神经网络的一层,循环神经网络可以看作在时间维度上权值共享的神经网络。
2.2 代码实现
使用矩阵的推导。
def get_params(embedding_size, output_size, num_hiddens, device):
"""
获取RNN的参数
Args:
embedding_size: 词嵌入的维度
output_size: 输出的维度
num_hiddens: 隐藏层大小
device: 训练设备
Returns:
参数的元组
"""
num_inputs = embedding_size
num_outputs = output_size
def normal(shape):
return torch.randn(size=shape, device=device) * 0.1
W = normal((num_inputs, num_hiddens))
U = normal((num_hiddens, num_hiddens))
b_h = torch.zeros(num_hiddens, device=device)
V = normal((num_hiddens, num_outputs))
b_q = torch.zeros(num_outputs, device=device)
params = [W, U, b_h, V, b_q]
for param in params:
param.requires_grad_(True)
return params
三、应用模式
3.1 序列到类别模式
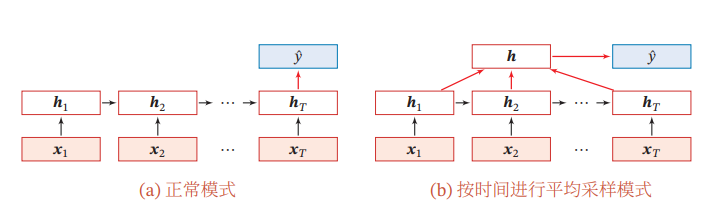
提示
主要用于序列数据的分类:输入数据为序列,输出为类别。
输入的样本x1:T=(x1,...,xT)为一个长度为T的序列,输出类别y∈{1,...,C},将样本x,按不同时刻输入到循环神经网络中,得到不同时刻的隐藏状态h1,...,hT,可以将hT看作整个序列的最终表示,并输入给分类器g(⋅)进行分类。
如上图所示,除了使用最后时刻的状态作为整个序列的表示,也可以使用整个状态的所有状态进行平均,并使用这个平均状态作为整个序列的表示,即y^=g(T1t=1∑Tht)
3.2 同步的序列到序列模式
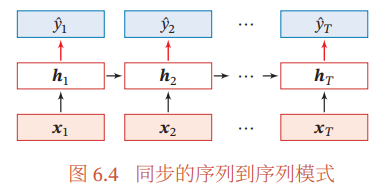
提示
主要用于序列标注任务,即每一时刻都有输入和输出,输入序列和输出序列的长度相同。
输入的样本x1:T=(x1,...,xT)为一个长度为T的序列,输出为序列y1:T=(y1,...,yT)。将样本x,按不同时刻输入到循环神经网络中,得到不同时刻的隐藏状态h1,...,hT,每个时刻的隐状态ht代表了当前时刻的和历史的信息,并输入给分类器g(⋅)得到当前时刻的标签y^,即y^t=g(ht),∀t∈[1,T].
3.3 异步的序列到序列模式
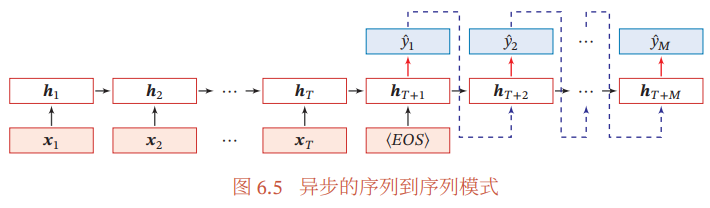
令f1(⋅)和f2(⋅)分别为编码器和解码器的循环神经网络,则编码器-解码器模型可以写为:
ht=f1(ht−1,xt),∀t∈[1,T]
hT+t=f2(hT+t−1,y^t−1),∀t∈[1,M]
y^t=g(hT+t),∀t∈[1,M]
其中g(⋅)为分类器,y^t为预测输出y^t的向量表示。 在解码器通常采用自回归模型,每个时刻的输入为上一时刻的预测结果y^t−1。如上图所示,其中<EOS>表示输入序列的结束,虚线表示将上一时刻的输出作为下一时刻的输入。
提示
异步的序列到序列模式也称为编码器-解码器模型。即输入序列和输出序列不需要严格的对应关系,也不需要保持相同的长度,例如机器翻译任务。
输入的样本x1:T=(x1,...,xT)为一个长度为T的序列,输出为长度为M的序列y1:M=(y1,...,yM)。
异步的序列到序列模式一般通过先编码后解码的方式来实现,先将样本x按不同时刻输入到一个循环神经网络(编码器)中,得到其编码hT,然后再使用另一个循环神经网络(解码器),得到输出序列y^1:M。为了建立输出序列之间的依赖关系,再解码器中通常使用非线性的自回归模型。
四、参数学习
循环神经网络的参数可以通过梯度下降的方法来进行学习。
以随机梯度下降为例,给定一个训练样本(x,y),其中x1:T=(x1,...,xT)为长度是T的输入序列,y1:T=(y1,...,yT)是长度为T的标签序列,每个时刻t都有一个监督信息yt,我们定义时刻t的损失函数为
Lt=L(yt,g(ht))
其中g(ht)为第t时刻的输出,L为可微分的损失函数,如交叉熵等,整个序列的损失函数为
L=t=1∑TLt
则整个序列的损失函数L关于参数U的梯度为
∂U∂L=t=1∑T∂U∂Lt
即每个时刻损失Lt对参数U的偏导数之和。
BPTT和RTRL比较:在循环神经网络中,一般网络输出维度要远低于输入维度,因此BPTT算法的计算量会小,但是BPTT算法需要保存中间所有时刻的中间梯度,空间复杂度高。RTRL算法不需要梯度回传,因此非常适用于需要在线学习或无限序列的任务中。
4.1 随时间反向传播算法 BPTT
算法主要思想:通过类似前馈神经网络的误差反向传播算法来计算梯度。
BPTT算法将循环神经网络看作一个展开的多层前馈网络,其中“每一层”对应循环网络中的“每个时刻”。这样,循环神经网络可以按照前馈神经网络中的反向传播算法计算参数梯度。在“展开”的前馈神经网络中,所有层的参数是共享的,因此参数的真实梯度是所有“展开层”的参数梯度之和。
计算偏导数U∂Lt:首先计算第t时刻损失对参数U的偏导数。
因为参数U和隐藏层在每个时刻k(1≤k≤t)的净输入zk=Uhk−1+Wxk+b有关(根据前向传播计算公式),因此t时刻的损失函数Lt关于参数uij的梯度为(链式法则):
uij∂Lt=k=1∑t∂uij∂+zk∂zk∂Lt
其中∂uij∂+zk为直接偏导数,即zk=Uhk−1+Wxk+b中hk−1保持不变,对uij求偏导数,得到
∂uij∂+zk=[0,...,[hk−1]j,...,0]
其中[hk−1]j为第k−1时刻隐状态的第j维。
定义误差项δt,k=∂zk∂Lt为第t时刻的损失对第k时刻隐藏层神经层的净输入zk的导数,则当1≤k<t时
δt,k=∂zk∂Lt=∂zk∂hk∂hk∂zk+1∂zk+1∂Lt
因此有
δt,k=diag(f′(zk))UTδt,k+1
将δt,k、∂uij∂+zk代入到uij∂Lt中得到
uij∂Lt=k=1∑t[δt,k]i[hk−1]j
写成矩阵形式有
U∂Lt=k=1∑tδt,khk−1T
代入到∂U∂L,得到整个序列的损失函数L关于参数U的梯度
∂U∂L=t=1∑Tk=1∑tδt,khk−1T
同理可得L关于权重W和偏置b的梯度为
∂W∂L=t=1∑Tk=1∑tδt,kxkT
∂b∂L=t=1∑Tk=1∑tδt,k
误差随时间进行反向传播算法的示例:
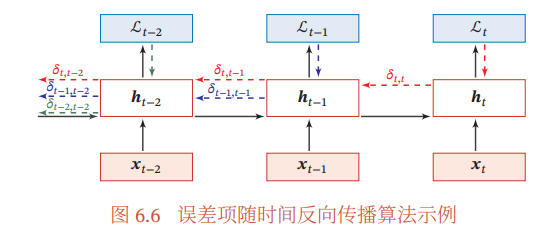
由上述推导过程可知,在BPTT算法中,参数的梯度需要在一个完整的“前向”计算和“反向”计算后才能得到并进行参数更新。
4.2 实时循环学习算法 RTRL
实时循环学习通过前向传播的方式来计算梯度。
假设循环神经网络中第t时刻的状态为ht+1为
ht+1=f(zt+1)=f(Uht+Wxt+1+b)
其中关于参数uij的偏导数为
∂uij∂ht+1=(∂uij∂+zt+1+∂uij∂htUT)∂zt+1∂ht+1
∂uij∂ht+1=(∂uij∂+zt+1+∂uij∂htUT)diag(f′(zt+1))
RTRL算法从第1个时刻开始,除了计算循环神经网络的隐状态之外,还依次前向计算偏导数∂uij∂h1,∂uij∂h2,∂uij∂h3,...
假设在第t时刻存在一个监督信息,其损失函数为Lt,可以同时计算损失函数对uij的偏导数
∂uij∂Lt=∂uij∂ht∂ht∂Lt
这样可以在t时刻,实时计算损失Lt关于参数U的梯度,并更新参数。参数W和b同样按上述方法实时计算。
参考文献
[1] 邱锡鹏,神经网络与深度学习,机械工业出版社,https://nndl.github.io/, 2020.
[2] 深度学习(三):详解循环神经网络RNN,含公式推导open in new window
[3] 动手学深度学习open in new window
[4] 零基础入门深度学习(5) - 循环神经网络open in new window