长短期记忆网络
长短期记忆网络是循环神经网络的一个变体,可以有效的解决简单循环神经网络的梯度爆炸或消失问题。
LSTM的改进主要在以下两个方面。
新的内部状态
LSTM网络引入一个新的内部状态ct∈RD,新的内部状态专门进行线性的循环信息传递,同时(非线性地)输出信息给隐藏层地外部状态ht∈RD,内部状态ct通过下面公式计算:
ct=ft⊙ct−1+it⊙ct
ht=ot⊙tanh(ct)
其中f(t)∈[0,1]D、it∈[0,1]D、ot∈[0,1]D为三个门来控制信息传递的路径;⊙为向量元素乘积;ct−1为上一时刻的记忆单元;ct∈RD是通过非线性函数得到的候选状态:
ct=tanh(Wcxt+Ucht−1+bc)
在每个时刻t,LSTM网络的内部状态ct记录了到当前时刻为止的历史信息。
门控状态
LSTM网络引入门控机制来控制信息传递的路径。三个门分别为输入门it、遗忘门ft和输出门ot。这三个门的作用为
遗忘门ft 控制上一个时刻的内部状态ct−1需要遗忘多少信息。
输入门it 控制当前时刻的候选状态ct有多少信息需要保存。
输出门ot 控制当前时刻的内部状态ct有多少信息需要输出给外部状态ht。
当ft=0,it=1时,记忆单元将历史信息清空,并将候选状态向量ct写入。但此时记忆单元ct依然和上一时刻的历史信息相关。
当ft=1,it=0时,记忆单元将复制上一时刻的内容,不写入新的信息。
提示
LSTM网络中的“门”是一种“软”门,取值在(0, 1)之间,表示以一定的比例允许信息通过.三个门的计算方式为:
it=σ(Wixt+Uiht−1+bi)
ft=σ(Wfxt+Ufht−1+bf)
ot=σ(Woxt+Uoht−1+bo)
其中σ(⋅)为Logistic函数,其输出区间为(0,1),xt为当前时刻的输入,ht−1为上一时刻的外部状态。
网络结构
LSTM网络的循环单元结构如下图所示,其计算过程为:
- 1.首先利用上一时刻的外部状态ht−1和当前时刻的输入xt,计算出三个门,以及候选状态ct
- 2.结合遗忘门ft和输入门it来更新记忆单元ct
- 3.结合输出门ot,将内部状态的信息传递给外部状态ht
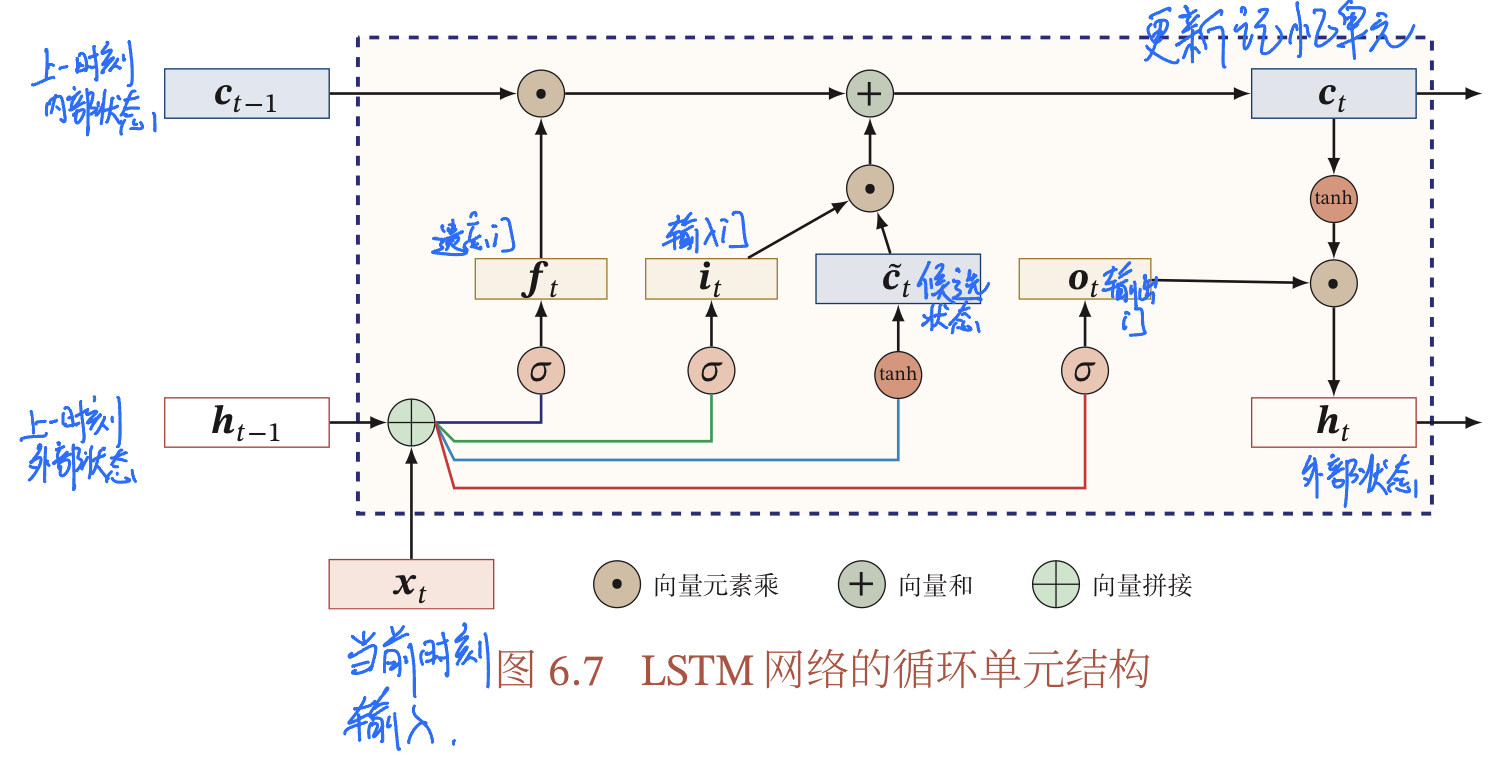
通过上述LSTM循环单元,整个网络可以建立较长举例的时序依赖关系,之前的公式可以简单描述为
⎣⎡ctotitft⎦⎤=⎣⎡tanhσσσ⎦⎤(W[xtht−1]+b)
ct=ft⊙ct−1+it⊙ct
ht=ot⊙tanh(ct)
其中xt∈RM为当前时刻的输入,W∈R4D×(M+D)和b∈R4D为网络参数。
提示
循环神经网络中的隐状态h存储了历史信息,可以看作一种记忆(Memory)。在简单循环网络中,隐状态每个时刻都会被重写,因此可以看作一种短 期记忆(Short-Term Memory)在神经网络中,长期记忆(Long-Term Memory)可以看作网络参数,隐含了从训练数据中学到的经验,其更新周期要远远 慢于短期记忆.而在LSTM网络中,记忆单元c可以在某个时刻捕捉到某个关键信息,并有能力将此关键信息保存一定的时间间隔.记忆单元c中保存信息的生命周期要长于短期记忆h,但又远远短于长期记忆,长短期记忆是指长的“短期记忆”.因此称为长短期记忆(LongShort-Term Memory).
一般在深度网络参数学习时,参数初始化的值一般都比较小。但是在训练 LSTM 网络时,过小的值会使得遗忘门的值比较小。这意味着前一时刻的信息大部分都丢失了,这样网络很难捕捉到长距离的依赖信息。并且相邻时间间隔的梯度会非常小,这会导致梯度弥散问题。因此遗忘的参数初始值一般都设得比较大,其偏置向量bf设为1或2。
相关变体
目前主流的 LSTM 网络用三个门来动态地控制内部状态应该遗忘多少历史信息,输入多少新信息,以及输出多少信息。我们可以对门控机制进行改进并获 得LSTM网络的不同变体。
无遗忘门的LSTM网络
最早提出的 LSTM 网络是没有遗忘门的,其内部状态的更新为
ct=ct−1+it⊙ct
记忆单元c会不断增大.当输入序列的长度非常大时,记忆单元的容量会饱和,从而大大降低LSTM模型的性能。
peephole连接
另外一种变体是三个门不但依赖于输入xt和上一时刻的隐状态ht−1,也依赖于上一个时刻的记忆单元ct−1,即
it=σ(Wixt+Uiht−1+Vict−1+bi)
ft=σ(Wfxt+Ufht−1+Vfct−1+bi)
ot=σ(Woxt+Uoht−1+Voct+bo)
其中Vi、Vf和Vo为对角矩阵。
耦合输入门和遗忘门
LSTM网络中的输入门和遗忘门有些互补关系,因此同时用两个门比较冗余。为了减少LSTM网络的计算复杂度,将这两门合并为一个门。令ft=1−it,内部状态的更新方式为
ct=(1−it)⊙ct−1+it⊙ct
代码实现
矩阵实现
使用nn.Linear实现