GeDi Generative Discriminator Guided Sequence Generation
论文名称
GeDi: Generative Discriminator Guided Sequence Generation
会议: EMNLP2021
Abstract
虽然大规模的语言模型(LM)能够很好地模仿自然语言的分布,以生成真实的文本,但很难控制它们生成哪些分布区域。这一点尤其成问题,因为用于训练大型语言模型的数据集通常含有明显的毒性、仇恨、偏见和消极性。解决这个问题的一个有希望的方法是使用判别器来指导LMs的解码,但现有的这个方法太慢了,对许多应用来说在实践中是有用的。我们提出的GeDi是一种明显更有效的基于判别器的指导解码方法。GeDi通过贝叶斯规则计算所有可能的下一个标记的分类概率,在每一步指导生成;一个是以期望属性或控制代码为条件,另一个是以不期望属性或反控制代码为条件。我们发现,GeDi提供的可控性与以前的可控生成方法相当,甚至更好。在我们的实验中,GeDi的生成速度明显快于之前唯一实现可控性的方法。我们还表明,GeDi可以使GPT-2和GPT-3的毒性大大降低,同时保持语言的流畅性,而不会明显牺牲生成速度。最后,我们发现只对三个主题进行训练的GeDi可以让我们从一个关键词中可控地生成新的主题。
1 Introduction
随着Transformers(Vaswani等人,2017)和大规模训练(Radford等人,2017,2018,2019;Brown等人,2020)的出现,自然语言生成有了很大进步。像GPT-2(Radford等人,2019)和GPT-3(Brown等人,2020)这样的大型语言模型(LM)能够很好地学习其训练集的分布,以生成真实的文本。然而,在生成过程中简单地模仿训练数据的分布有很多缺点(Bender等人,2021);大规模的文本训练集是从网络上抓取的,其中充满了毒性、偏见和错误信息。控制生成的方法对于使在这种数据上训练的LM更安全、对下游应用更有用是有价值的。
现有的控制LM的方法有局限性。诸如CTRL(Keskar等人,2019年)这样的类条件型LMs(CC-LMs)试图通过对控制代码进行调节来控制文本生成,控制代码是一个代表数据源的属性变量。然而,使用特定的控制代码会减少不同提示的样本多样性,因为样本一般会与控制代码的数据源相似。
另一种控制LM的方法是使用判别器来指导解码,但现有的方法在计算上非常密集。加权解码(Holtzman等人,2018)需要将候选的下一个token送入一个判别器,因此在计算上与要重新加权的标记数量呈线性扩展。Plug and Play LM(Dathathri等人,2020年,PPLM)利用鉴别器的梯度,在每个时间步骤中对生成的LM的潜状态进行多达10次的更新,这也使得它比直接从LM生成慢了许多倍。
我们提出的GeDi是一种明显更有效的判别器引导解码算法。我们提出的方法使用类别条件LM作为生成判别器(GeDis)来引导语言生成,以达到预期属性。我们使用GeDis在生成过程中使用贝叶斯规则计算所有候选下一个标记的分类可能性,与使用相同大小的标准(非生成)判别器计算大词汇量相比,节省了数千倍的计算。然后,我们展示了这些可能性如何通过加权解码和过滤来指导大型语言模型的解码工作。
我们的实验结果验证了GeDi在各种环境下控制生成的能力,同时保持与强大的语言模型相同的语言质量。我们应用GeDi(345M参数)来指导更大的语言模型的解码,并发现:
- GeDi在训练和推理方面的计算效率都很高。在我们的实验中,GeDi引导的解码比使用Dathathri等人(2020)的默认设置的GPT2应用PPLM快以上。此外,在单个GPU上微调不到一天的较小的GeDis对于控制较大的语言模型是有效的,而且计算效率高。
- 对电影评论的情感进行训练的GeDi可以生成具有积极或消极语气的图书文本,其效果优于或等同于现有的基线[第5.1节]。对积极性的引导也有潜在的应用,可以使LMs更加友好。
- GeDi能够大大减少GPT-2和GPT-3生成的毒性[第5.2节],与直接从GPT-2和GPT-3生成相比,没有牺牲语言质量,这表明应用于更安全的语言建模。
- 在只有3个主题的数据集上训练的GeDi可以归纳到新的控制代码zero-shot[第5.3节],使他们能够引导生成各种主题。
2 Background
2.1 Language modeling
语言模型(LMs)依靠自动回归因子化来进行密度估计和序列生成。具有参数θ的自动回归序列模型为序列,通过使用链式规则对其进行因子化,应用
模型可以通过迭代预测下一个符号的分布,给以前的符号分配概率。从语言模型生成需要从中迭代采样,然后将作为下一步的输入反馈到模型中。
2.2 Class-Conditional Language modeling
类条件语言模型(CC-LMs),如CTRL(Keskar等人,2019)是语言模型生成的一种方式,同时对一个属性变量进行调节。CC-LMs预测一个概率分布,其中是一个类变量或 "控制代码",描述中文本的一个属性,例如,可以描述情感或主题。CC-LM的自动回归因子化是由以下公式给出的
当在一个序列为的训练集上训练CC-LM时,每个序列都与控制代码配对,这是序列的标签或类别。训练LM是为了最小化平均负对数似然函数,给出公式如下:
除了类条件生成,CCLM还可以通过应用贝叶斯规则计算来作为生成性分类器,正如Keskar等人(2019年)对来源归属的做法。
3 GeDi
一个属性判别器可以用来指导语言模型的解码工作。例如,给定上下文和基础语言建模分布,鉴别器可以为每个可能的下一个标记计算。然后,可以使用加权解码启发式引导生成,方法是
其中ω>1,以使生成更偏向于所需的类别。方程(4)的右边是对词汇中所有的归一化,得到。对于标准判别器来说,应用这个方法来指导解码是非常低效的;使用带有判别器头的语言模型,如GPT(Radford等人,2018)或BERT(Devlin等人,2019)来计算,需要将每个可能的输入送入分类器,因此需要对词汇集进行前向传递,以计算网络的最终隐藏状态。GeDi的动机是用生成判别器有效地计算,而不需要为每个候选的下一个符号单独进行前向传递。
GeDi假设我们有一个CC-LM,其中有期望的控制代码和不期望或反控制代码,并使用和之间的对比来指导从LM中取样,从而得到。具体来说,在生成过程中预测下一个标记时,GeDi使用这种对比来计算每个候选下一个标记属于所需类别的概率,由给出。当使用CC-LMs作为GeDis时,通过在生成过程中对部分序列应用贝叶斯规则,可以非常有效地计算出这个分布。
当在序列生成过程中在线计算时,模型已经计算了前一个时间步骤中任何的,它只需要计算。 如图1所示,这可以通过两个平行的前向传递来计算;一个是对的调节,一个是对的调节(都是对同一个的调节)。相比之下,带有二进制判别器头的LM需要计算前向传递来计算所有候选下一个标记的属性概率,如图2所示。虽然GeDi使用的输出层比带鉴别器头的LM大,但通过带softmax头的LM计算2个前向传递(在GeDi的情况下)仍然比通过带二进制鉴别器头的LM计算前向传递要高效许多倍,特别是对于现代Transformer架构(或任何有许多隐藏层的架构),计算最终隐藏状态是前向传递计算的瓶颈。虽然一个非常小的判别器也可以用来有效地指导生成,但我们在实验中发现,这并不能提供强大的属性控制。

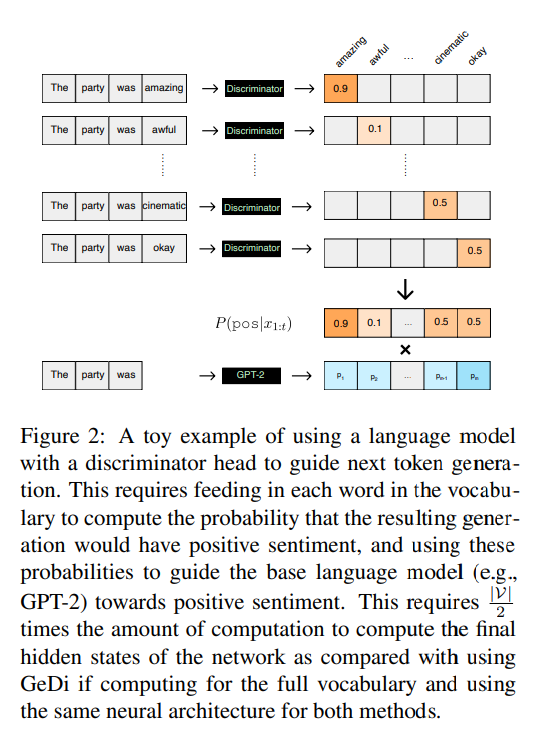
在实践中,将方程(5)应用于长序列往往会导致在后期序列为所有候选的下一个词分配或的分类概率出现校准不良的分布,这没有提供有用的信号。我们通过对当前序列长度的概率进行归一化来解决这个问题。为了计算GeDi指导下的解码的,我们使用
其中,由于我们使用平衡类进行训练,所以省略了类的预设值。通过对的有效估计,可以用公式(4)有效地指导LM生成。这内在地对比了以和为条件的预测,使和的共同属性被抵消,更有效地允许所描述的属性跨域转移。例如,如果捕捉的是正面电影评论的分布,而捕捉的是负面电影评论的分布,对这两个分布的对比将取消针对电影评论的预测,更好地概括正面性和负面性的概念。除了方程(4),我们还应用了附录A中描述的过滤启发式,该启发式将下一个token分布中较低的部分抹去。我们在算法1中总结了GeDi。
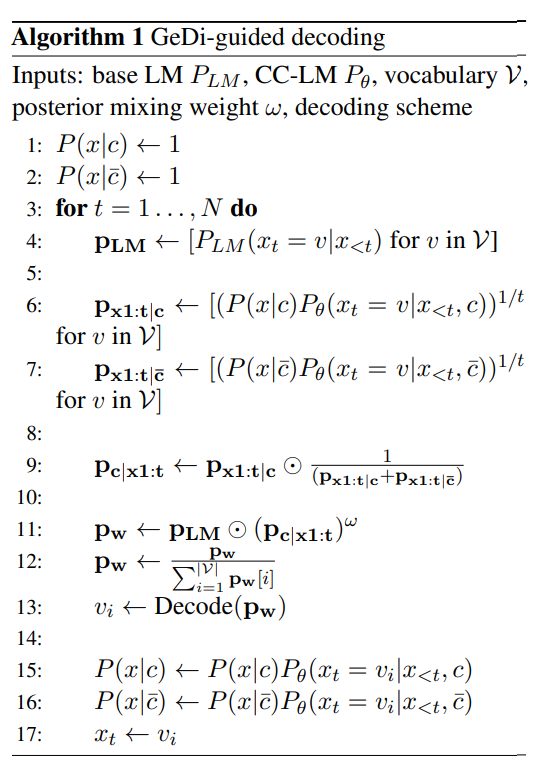
3.1 Multi-topic GeDi
为了有效地将GeDi扩展到多类环境中,我们建议将每个分类任务重构为二进制分类,对每个类别使用控制代码和反控制代码。每个类别的控制代码由 "true"与类别名称相连接给出,而反控制代码由 "false"与类别名称相连接给出。然后,CC-LM可以对类名是否与文本相对应进行分类。例如,如果CC-LM处理以下两个序列。
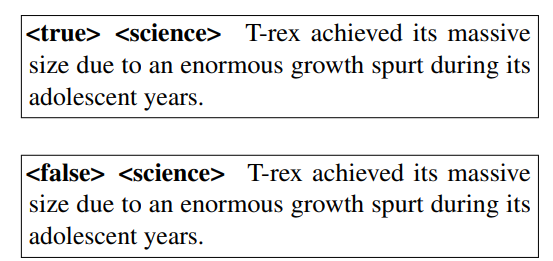
通过使用公式(6),它可以将文本分类为true或false,以确定类别(在此情况下为 "科学")是否与文本的类别相匹配。在训练过程中,该模型看到相同数量的真配对(文本对应于类别)和随机选择的假配对。在模型训练完成后,可以应用二进制GeDi引导的解码,使用和,并使用所需的类别名称作为序列中的第一个标记()。这也使得有可能形成新的控制码zero-shot;一个在训练中从未见过的新主题词可以被选择来代替()。当GeDi被初始化为一个预训练的语言模型时,这个方法很有效,因为该模型在预训练中已经学会了许多主题的嵌入,可以作为zero-shot控制码使用。
4 Related Work
可控文本生成的方法可大致分为两类:直接训练或微调模型以实现可控生成(Chan等人,2021;Madotto等人,2020;Keskar等人,2019;Ziegler等人。2019;Rajani等人,2019;Fan等人,2018;Ficler和Goldberg,2017;Yu等人,2017;Hu等人,2017)或使用判别器来指导解码(Ghazvininejad等人,2017;Holtzman等人,2018;Dathathri等人,2020)。Keskar等人(2019年)用放置在每个序列开始的预定义控制代码训练CC-LM。GeDi也使用CC-LMs,但不是直接从它们生成,而是使用它们作为判别器来指导来自另一个语言模型的解码。这比以前的判别器指导解码的方法在计算上要高效得多。Holtzman等人(2018年)应用判别器对beam搜索进行重新加权,要求所有的候选标记都要通过判别器,与重新加权的标记数量成线性比例。PPLM(Dathathri等人,2020)在语言模型的最后一个隐藏层之上训练一个属性模型,并反向传播梯度以更新模型的隐藏状态。这在计算上是很密集的,因为它需要在每个生成步骤中进行多次前向和后向传递。例如,像Dathathri等人(2020)所做的那样,应用PPLM的10个更新步骤,与第一个解码时间步的基础LM生成相比,需要额外的20折计算(10个前向传递,10个后向传递)。这个系数也会随着序列长度的增加而增加,因为PPLM会更新之前存储的键和值。相比之下,GeDi只增加了与基础LM大小无关的恒定开销,如果GeDi比基础LM小得多,这个恒定开销将是最小的。
GeDi也与计算语用学的合理言语行为框架有关(Frank和Goodman,2012;Goodman和Stuhlmüller,2013),其中 "听者 "模型和 "说者 "模型交互生成一个序列,以便听者能够恢复输入。GeDi与基于干扰物的语用学(Andreas and Klein, 2016; Cohn-Gordon et al., 2018; Shen et al., 2019)关系最为密切,其中一个模型处理一个真实输入和一个干扰物输入,并使用贝叶斯规则来产生符合真实输入而非干扰物输入的文本。GeDi与之前基于语用学的方法不同,它在单一属性上训练一个单独的类条件语言模型(作为听众),允许该属性被隔离,并使用它来指导单独的语言模型(作为说话者)的生成。
以前的其他工作试图理解和解决语言生成中的毒性和仇恨言论。RealToxictyPrompts(Gehman等人,2020)利用一组网络文本提示,利用不同语言模型的生成,给出了对毒性的自动评估。(Gehman等人,2020)还测试了减轻毒性的方法,并发现应用PPLM比更简单的基于解码的解毒方法(如脏话过滤器)更有效。Xu等人(2020)开发了一种人类在循环中的方法,用于对抗性地探测对话代理中的毒性反应,并训练一个模型在遇到潜在的不安全探测时给出预设的反应。其他工作集中于从语言模型中去除性别偏见(Bordia和Bowman,2019;Dinan等人,2020;Bolukbasi等人,2016)。与解决生成中的毒性问题相关的是毒性检测,可以使用Perspective API或使用在标记的毒性数据集(如Jigsaw Toxic Comment Classification Dataset)上训练的分类器(Borkan等人,2019)进行检测。毒性检测是困难的,因为毒性标记是主观的,而且注释者的一致性往往很差(Waseem,2016;Ross等人,2017)。此外,现有的毒性分类器往往有偏见,因为它们高估了提到性取向或少数种族的文本的毒性(Dixon等人,2018;Sap等人,2019;Hutchinson等人,2020)。