Do Transformers Really Perform Bad for Graph Representation
论文名称
Do Transformers Really Perform Bad for Graph Representation?
会议: NIPS2021
Abstract
Transformer结构已经成为许多领域的主要选择,例如自然语言处理和计算机视觉。然而,与主流的GNN变体相比,它在流行的graph-level的排行榜上并没有取得具有竞争力的表现。因此,Transformer如何很好地进行图表示学习仍然是一个谜。
通过提出基于标准Transformer架构的graphhormer来解决这个谜题,它可以在广泛的图表示学习任务中取得优异的结果,特别是在最近的OGB大规模挑战中。
我们在图中使用Transformer的关键点是,必须有效地将图的结构信息编码到模型中。
为此提出了几种简单而有效的结构编码方法,以帮助Graphormer更好地建模图结构数据。
此外还从数学上描述了Graphormer的表达能力,并展示了通过编码图的结构信息的方式,许多流行的GNN变体都可以作为Graphormer的特殊情况。
Introduction
Transformer被公认为是建模序列数据(如自然语言和语音)的最强大的神经网络。 基于Transformer构建的模型变体在计算机视觉和编程语言方面也表现出了出色的性能。 然而,Transformer仍然不是图表示排行榜的实际标准。 有许多尝试将Transformer引入图领域,但唯一有效的方法是通过softmax attention来替换经典GNN变体中的一些关键模块(例如,特性聚合)。 因此,Transformer架构是否适用于图的建模以及如何使其适用于图表示学习仍然是一个悬而未决的问题。
在本文中,我们通过设计Graphormer给出了肯定的答案,它直接构建在标准的Transformer上,并在广泛的图形级预测任务中实现了最先进的性能,包括最近的Open Graph Benchmark大规模挑战(OGB-LSC),以及一些流行的排行榜(如OGB,Benchmarking-GNN)。 Transformer最初是为序列建模而设计的。为了在图中利用它的功能,我们认为关键是将图的结构信息适当地纳入到模型中。注意,对于每个节点i,自注意只计算i与其他节点的语义相似度,而不考虑节点上反映的图的结构信息和节点对之间的关系。Graphormer合并了几种有效的结构编码方法来利用这些信息,如下所述。
首先,我们在Graphormer中提出一种中心性编码来捕捉图中的节点重要性。在一个图中,不同的节点可能有不同的重要性,例如,名人被认为比社交网络中的大多数网络用户更有影响力。但是这些信息并没有在self-attention模块中体现出来,它主要通过节点语义特征来计算相似性。为了解决这个问题,我们建议在Graphormer中编码节点中心性。特别地,我们利用度中心性进行中心性编码,根据度为每个节点分配一个可学习向量,并添加到输入层的节点特征中。实证研究表明,简单中心性编码对Transformer图形数据建模是有效的。
其次,我们在Graphormer中提出了一种新的空间编码来捕捉节点之间的结构关系。图结构数据与其他结构化数据(如语言、图像)的一个显著的几何特性是,不存在嵌入图的规范网格。事实上,节点只能位于非欧几里得空间中,并且由边连接。为了对这种结构信息进行建模,我们根据每个节点对的空间关系分配一个可学习的嵌入。文献中的多种测量方法可以用于建模空间关系。一般来说,我们使用任意两个节点之间的最短路径距离作为演示,它将被编码为softmax attention中的偏差项,并帮助模型准确地捕捉图中的空间依赖性。此外,有时在边缘特征中包含额外的空间信息,例如分子图中两个原子之间的键的类型。我们设计了一种新的边缘编码方法,进一步将这种信号引入Transformer层。具体地说,对于每个节点对,我们沿最短路径的计算边缘特征的点积和可学习嵌入的平均值,然后将其用于attention module。有了这些编码,Graphormer可以更好地建模节点对的关系并表示图。
通过使用上面提出的编码,我们进一步从数学上表明,由于许多流行的GNN变体只是它的特殊情况,Graphormer具有很强的表达能力。该模型的巨大容量导致在实践中广泛的任务上的最先进的性能。在最近的Open Graph Benchmark大规模挑战(OGB-LSC)中的大规模量子化学回归数据3中,就相对误差而言,Graphormer的表现比大多数主流GNN变体高出10%以上。在其他流行的图表示学习排行榜上(如MolHIV, MolPCBA, ZINC),Graphormer也超过了之前的最佳结果,展示了Transformer结构的潜力和适应性。
Preliminary
本节主要回顾图神经网络、Transformer.
主要结构如下图所示: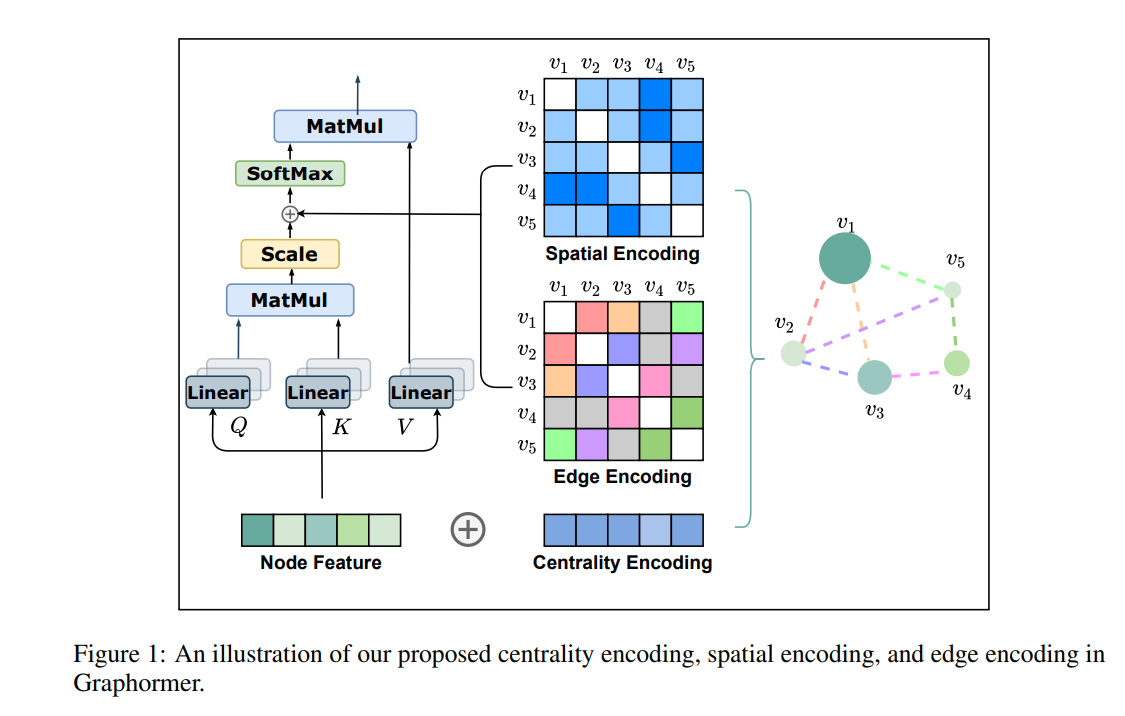
Graph Neural Network(GNN)
表示图,其中,且为节点数量,使节点的特征向量为,GNN旨在学习节点和图的表示。
典型地,现代GNN通过聚合节点的一阶或高阶的邻居的表示来迭代更新节点的表示。
我们将作为节点在第层的表示,并且定义,第次聚合迭代可以用AGGREGATE-COMBINE步骤来表示:
其中,为节点的一阶或更高阶邻居,AGGREGATE函数被用于聚合邻居的信息。一般的AGGREGATE函数包含,,,被用于不同结构的GNNs. Combine函数主要用于将来自邻居的信息融合到节点表示中。
除此之外,对于图表示的任务,READOUT函数被设计用于聚合最终迭代的节点特征到整个图的表示中。READOUT可以通过简单的排列不变函数(如求和)或更复杂的图级池化函数来实现。
Transformer
Transformer结构由Transformer层组成,每个Transformer层有两部分:自注意力机制模块和position-wise feed-forward network(FFN)。
令表示自注意力模块的输入,为隐藏层的维度,为位置的隐藏表示,输入的被三个矩阵,,投影到对应的表示,,. 自注意力层计算如下:
其中A是捕捉queries和keys相似性的矩阵。为了简化表示,我们考虑单头自注意力机制并且假设.对多头注意力的扩展是标准且直接的,为了简单起见,我们省略了偏见术语。
Graphormer
在本节中,我们将介绍用于图形任务的Graphormer。
首先,我们详细阐述了Graphormer中的几个关键设计,它们作为神经网络中的归纳偏差来学习图表示。我们进一步提供了Graphormer的详细实现。最后,我们表明我们提出的Graphormer更强大,因为流行的GNN模型是它的特殊情况。
Structural Encodings in Graphormer
Centrality Encoding
上述等式根据节点间的语义相关性计算注意力分布。然而,node centrality(衡量节点在图中的重要性)通常是图理解的一个强烈信号。 例如,拥有大量粉丝的名人是预测社交网络趋势的重要因素。这些信息在当前的注意力计算中被忽略了,我们认为它对Transformer模型应该是一个有价值的信号。
在Graphormer中,我们使用 degree centrality,这是文献中标准的中心性度量之一,作为神经网络的附加信号。提出了一种Centrality Encoding,根据节点的入度和出度分配两个实值嵌入向量。 由于centrality encoding应用于每个节点,我们只需将其添加到节点特性中作为输入。
其中是可学习的嵌入向量,分别由和所指定,对于无向图,和可以统一为。 通过在输入中使用centrality encoding,softmax attention可以捕捉到queries和keys中的节点重要性信号。因此,该模型既能捕获注意力机制中的语义相关性,又能捕获注意力机制中的节点重要性。
Spatial Encoding
Transformer的一个优点是它的全局接收域。 在每个Transformer层中,每个token可以关注任何位置的信息,然后处理其表示。 但是这个操作有一个副作用,他的模型必须显式地指定不同的位置,或者在层中编码位置依赖(例如位置)。 对于顺序数据,要么给每个位置一个嵌入(即绝对位置编码)作为输入,要么在Transformer层中对任意两个位置的相对距离进行编码(即相对位置编码)。
但是,对于图,节点不是按顺序排列的。它们可以位于多维空间中,并由边连接。为了在模型中编码图的结构信息,我们提出了一种新的Spatial Encoding。 确切的说,对于任何图,我们考虑一个函数,它表明图中的和的Spatial Encoding。函数被定义为图中节点的连通性。
本篇论文中选择表示节点和之间的最短路径(SPD),若两个节点是连通的。如果不是,我们设置的输出结果为一个特殊值,例如-1。我们给每个(可行的)输出值分配一个可学习的标量,作为自注意力模块中的偏差项。 表示,其中是可学习的标量,其中对它索引,并在所有层共享。
这里我们讨论我们所提出的方法的几个好处:
- 与传统GNN相比,接受域被限制在邻居,我们可以看到在上面的公式中,Transformer层提供了一个全局信息,每个节点可以关注图中所有其他节点。
- 通过使用,单个Transformer层中的每个节点都可以根据图结构信息自适应地关注所有其他节点。例如,如果被认为是一个关于递减的函数,那么对于每个节点,模型可能会更多地关注它附近的节点,而较少关注远离它的节点。
Edge Encoding in the Attention
在许多图任务中,边也有结构特征,例如,在分子图中,原子对可能有描述它们之间键的类型的特征。 这些特征对图表示很重要,将它们与节点特征一起编码到网络中是必不可少的。
在以往的工作中,主要有两种边缘编码方法。
- 第一种方法是将边缘特征加入到关联节点的特征中。
- 第二种方法中,对于每个节点,其关联边的特征将与聚合中的节点特征一起使用。然而,这种利用边缘特征的方法只能将边缘信息传播到与其关联的节点上,这可能不是利用边缘信息来表示整个图的有效方法。
为了更好地将边缘特征编码到注意层中,我们提出了一种新的edge encoding。
注意机制需要估计每个节点对的相关性,我们认为连接它们的边应该在相关性中考虑。
对于每个有序的节点对(v_{i},v_{j}),我们寻找一条最短路径从到.计算边缘特征点积的平均值和沿路径的可学习嵌入。 本文提出的edge encoding通过偏置项将边缘特征引入注意力模块。
确切的说,我们进一步使用edge encoding 修改中的元素:
其中是的第n条边的特征,为其权重嵌入,是边缘特征的维数。
Implementation Details of Graphormer
Graphormer Layer
graphhormer是在经典Transformer编码器的原始实现的基础上构建的。此外,我们应用layer normalization(LN)和前馈块(FFN)在多头自注意力之前(MHA),而不是之后。 该修改已被当前所有Transformer实现一致采用,因为它可以带来更有效的优化
特别是对于FFN子层,我们将输入、输出和内层的维数设置为与d相同的维数。我们对Graphormer层的形式化描述如下:
Special Node
如前一节所述,提出了各种图池化函数来表示图嵌入。
受(Neural message passing for quantum chemistry)的启发,在Graphormer中,我们在图中添加了一个名为[VNode]的特殊节点,并分别在[VNode]和每个节点之间建立连接。