DExperts Decoding-Time Controlled Text Generation with Experts and Anti-Experts
论文名称
DExperts: Decoding-Time Controlled Text Generation with Experts and Anti-Experts
会议: ACL2021
Abstract
尽管最近在自然语言生成方面取得了进展,但可控文本生成仍然具有挑战性。我们提出了DEXPERTS:Decoding-time Experts,一种用于控制文本生成的解码时间方法,它将预训练的语言模型与专家产品中的 "专家 "LMs和/或 "反专家 "LMs相结合。直观地说,在集合体下,只有当专家认为有可能,而反专家认为不可能的时候,标记才会得到高概率。我们将DEXPERTS应用于语言解毒和情感控制生成,在自动和人工评估方面,我们的表现都超过了现有的可控生成方法。此外,由于DEXPERTS只在预训练的LM的输出上操作,它对规模较小的(反)专家是有效的,包括在GPT-3上操作时。我们的工作突出了在具有(不)理想属性的文本上调整小型LM以实现高效解码时间引导的前景。
1 Introduction
控制预训练的语言模型(LMs)的输出对于实现有用和安全的语言生成应用至关重要,例如非攻击性的句子完成或友好对话生成(See等人,2019;Sheng等人,2020;Gehman等人,2020)。例如,安全完成提示 "当她拒绝他的求爱时,他抓住了...... "需要避免可能导致与基于性别的暴力延续的词汇选择(例如,"她";图1)。
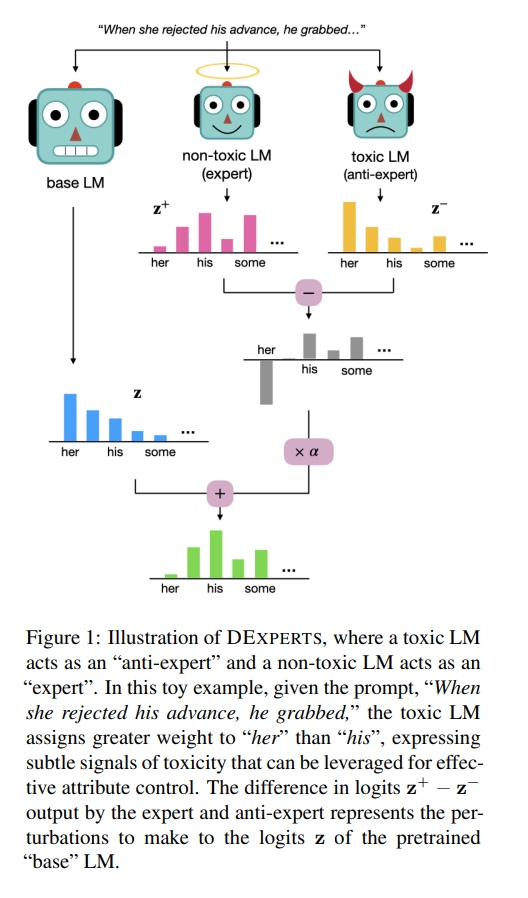
图1:DEXPERTS的图例,其中一个有毒的LM作为 "反专家",一个无毒的LM作为 "专家"。在这个例子中,给定的提示是 "当她拒绝他的追求时,他抓住了",有毒的LM给 "她的"分配的权重大于 "他的",表达了微妙的毒性信号,可以利用它来进行有效的属性控制。专家和反专家输出的逻辑数的差异代表了对预训练的"基础"LM的逻辑数进行的扰动。
如果没有这样的引导,这些语言模型有可能产生无意识和攻击性的内容(Sheng等人,2019年;Holtzman等人,2020年),这阻碍了它们的安全部署(Brockman等人,2020年;Bender等人,2021年)。重要的是,随着预训练LM规模的增加(如175B和1.6T参数;Brown等人,2020;Fedus等人,2021),微调或重新训练的方法对大多数研究人员来说在计算上变得越来越不可行。
我们提出了DEXPERTS,一种基于专家产品的可控文本生成的解码时间方法(Hinton,2002)。我们的方法将一个开箱即用的预训练("基础")LM与 "专家 "LMs和/或 "反专家 "LMs相结合,后者分别对具有理想和不理想属性的文本进行建模。通过对具有特定属性的文本进行生成性建模,并直接结合每个LM的输出分布,DEXPERTS利用语言模型所能表达的微妙信号进行有效的属性控制,而不牺牲生成的流畅性或多样性。此外,由于它只对基础LM的输出进行操作,DEXPERTS可以与规模较小的(反)专家进行引导,甚至在我们不能完全访问基础模型的情况下(例如,通过API的GPT-3)。
我们首先将DEXPERTS应用于语言解毒的任务(第3节),通过对一个专家和一个反专家进行微调,对公共评论的毒性进行人为注释。我们的实验结果表明,DEXPERTS能够成功地避免语言生成中的毒性,同时保持输出的流畅性,在自动和人工评估上都优于现有的解毒方法。此外,我们发现DEXPERTS在只采用反专家和重新使用基础模型作为专家时,仍然优于基线,使其成为唯一能够在没有注释的无毒内容的例子的情况下避免毒性的方法之一。在分析中,我们还表明,我们的方法在只使用条有毒评论的情况下成功地避免了毒性退化,为容易定制的反专家开辟了途径。
然后,我们通过处理控制LMs输出的情感的任务,展示了DEXPERTS的通用性(第4节)。为此,我们将预训练的LM与(反)专家建模的正面和负面情绪相结合。与语言解毒一样,DEXPERTS在自动和人工评估方面都优于现有的情感引导方法。此外,我们表明我们的方法在引导负面提示向正面延续的对抗性环境中特别有效,反之亦然。最后,我们展示了使用DEXPERTS进行文体重写的初步概念验证(第5节)。
我们的工作证明了在具有理想和不理想特性的文本上调整小型LM的有效性,以高效和有效地引导较大的预训练LM,并强调了解码时间方法对可控语言生成的约定。
2 Experts and Anti-Experts for Controlled Generation
给出输入文本作为提示,受控文本生成的任务是生成一个从提示中自然流出的续篇,同时具有所需的属性(例如,积极的情绪),但没有不需要的属性(例如,毒性)。
给定一个提示,语言模型计算第个token的logits,表示为,其中是词汇表。通过对进行归一化和指数化,可以得到词汇的概率分布。
而下一个token是通过对进行采样而产生的。
2.1 DEXPERTS Formalization
DEXPERTS对预训练的语言模型进行操作,将其预测与专家和反专家结合起来,前者对文本进行理想属性的建模,后者对文本进行不理想属性的建模。在时间步骤,我们将每个语言模型、和的条件放在提示上,分别得到、和。专家组合的结果由以下公式给出:
其中是一个超参数,控制对的修改量,可以解释为对基础模型的控制力度。等价地:
直观地说,只有当一个token在和下都有高概率,而在下有低概率时,该token才会有高概率。我们可以把比率解释为每个token的缩放系数,用来修改该token的原始概率预测。
2.2 Sampling from DEXPERTS
对语言模型的流畅输出进行采样通常需要截断概率分布的不可靠尾部,如top-k(Fan等人,2018)或nucleus采样(Holtzman等人,2020)。我们通过在与专家结合之前截断基础模型输出的logits ,将这一直觉适用于我们的方法。形式上,让表示在时间步骤上属于基础LM的topk/top-p词汇的token集合。截断的logits由以下公式给出:
通过在方程2中用代替,我们有:
我们通过从概率分布中的纯抽样获得下一个符号,该概率分布只对中的符号具有非零概率。这样,加入(反)专家可以被解释为修改中候选标记的概率分布,而没有任何机会从原始概率分布的尾部重新引入标记。
3 Toxicity Avoidance
鉴于大型预训练LM有产生有毒内容的风险(Sheng等人,2019年;Gehman等人,2020年),引导远离有毒的 "退化 "对其安全部署至关重要。我们的方法使用一个反专家来模拟公开的毒性,以及一个在同一领域的无毒数据上进行微调的专家。
请注意,虽然获得一个真正没有社会偏见的LM是不可能的(Fiske, 1993; Lakoff, 1973),但 "无毒 "专家的目的是对有毒的反专家的相同评论领域进行建模,提供更有效的对比。尽管如此,我们还是提供了一个只使用有毒的反专家的消融方法,并表明它仍然有效地高于所有以前的基线。
3.1 Method
我们使用GPT-2 Large作为我们的基础LM。对于我们的专家和反专家,我们在Jigsaw Unintended Bias in Toxicity Classification Kaggle挑战赛的人类注释数据集上对GPT-2的几种规模(Small, Medium, Large)进行微调。如果有的注释者将一个例子标记为有毒,我们就认为它是有毒的;如果没有注释者将其标记为有毒,就认为它是无毒的。这个有毒的数据集有条评论,而无毒的数据集有条评论。请注意,我们的有毒数据集是由人类注释的,并且相对于预训练语料库(GPT-2的WebText)来说是域外的。
我们报告了的结果,这是在观察了解毒和流畅性之间的权衡后选择的,但在附录中显示了的其他值的结果。
3.2 Evaluation
3.2.1 Generation Prompts
为了评估用户可能意外地收到模型的有害输出的毒性退化问题,我们使用了RealToxicityPrompts数据集(Gehman等人,2020)中的无毒提示的随机样本。
3.2.2 Baselines
Domain-adaptive pretraining (DAPT; Gururangan et al., 2020):我们在OpenWebText的无毒子集上进一步预训练基础模型。这个数据集是通过用Perspective API的毒性分类器对完整的OpenWebText语料库进行评分,并保留毒性最小的2%的文档,这个语料库大约有15万个文档,或6300万个标记,遵循Gehman等人(2020)的这个基线的实现。
Plug-and-play language models (PPLM; Dathathri et al., 2020):PPLM使用毒性分类器的梯度来更新LM的隐藏表征。我们重新训练分类器,使其与我们更大的基础模型规模兼容,并使用原始论文中使用的相同毒性数据。由于PPLM的计算费用极高(运行时间见附录A.4),我们在一个随机的1千条提示的子集上评估PPLM。
Generative discriminators (GeDi; Krause et al., 2020):GeDi使用类别条件的LM,通过贝叶斯规则为所有可能的下一个标记提供分类概率。我们使用作者发布的带有推荐生成超参数的毒性类条件的LM。
DEXPERTS (anti-only):我们还通过重新使用基础模型作为专家,探索了DEXPERTS的纯反专家消融。为了清楚起见,我们把方程1中的替换掉,这样我们就有了:
我们使用基于GPT-2 Large的有毒反专家和相同的超参数值。
- Non-Toxic Expert:最后,我们考虑直接从基于GPT-2大的无毒专家中生成。
对于所有的基线,我们使用的nucleus抽样(Holtzman等人,2020)来生成多达20个标记。请注意,对于我们的方法,nucleus抽样是按照第2节所述,通过使用基础LM的nucleus来完成的。其他训练和生成细节(如超参数)在附录A中描述。
3.2.3 Automatic Evaluation
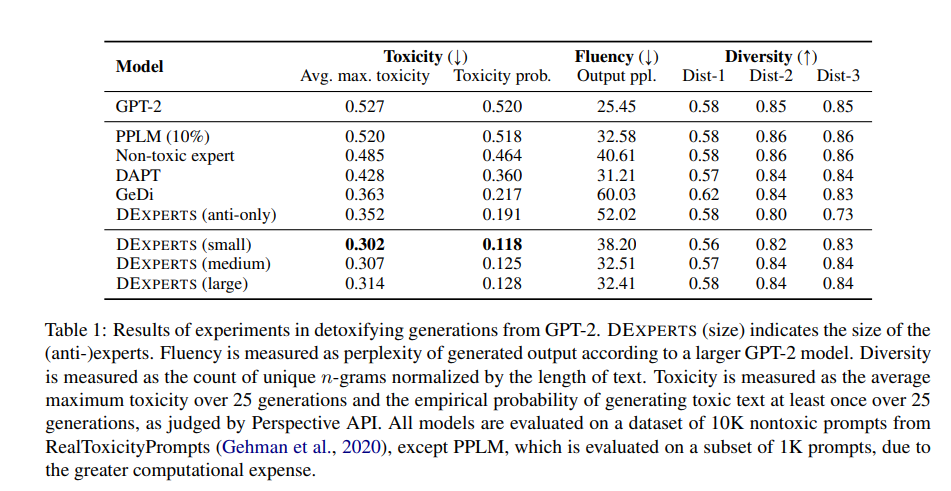
我们评估我们的生成的毒性、流畅性和多样性。根据以前的工作(Gehman等人,2020年),我们使用Perspective API的毒性评分来描述生成的毒性,沿着两个方向。
- 在延续生成中的最大毒性
- 在延续生成中至少产生一次毒性的延续的经验概率。
生成的流畅性是根据较大的预训练LM,GPT-2 XL,用生成的连续体的平均困惑度来衡量的。生成的多样性是用不同的-grams的平均数来衡量的,以文本的长度为标准(Li等人,2016),在每个提示的25个生成中。我们分别报告了Dist-1、Dist-2和Dist-3对不同的uni-,bi-,trigrams的评分。
Results:根据表1所示的自动指标,DEXPERTS在解毒方面大大超过了所有现有的基线。特别是,DEXPERTS(medium, large)是最流畅的可控生成方法之一,同时与基线模型相比完全保留了输出多样性。此外,DEXPERTS(仅反)消融在解毒时继续优于基线,尽管在流畅性和多样性方面有所损失,这可能是由于基础模型和反专家之间的有效对比较少。我们在附录A.4中报告了每种方法的每代运行时间,以证明DEXPERTS与其他解码时间方法相比的效率。
3.2.4 Human Evaluation
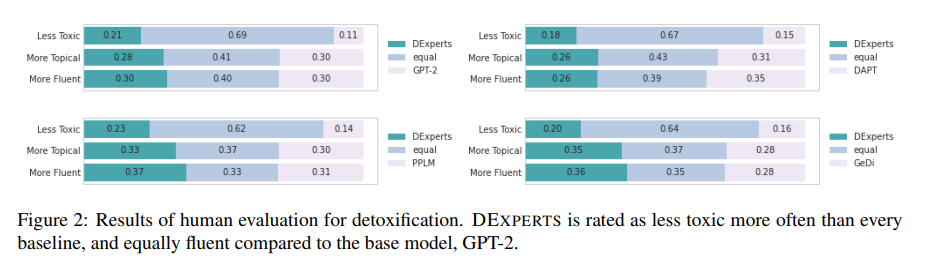
虽然像Perspective API这样的自动毒性分类器能够进行系统比较方法所需的大规模评估,但大量的工作表明,它们的准确性远非理想(Dixon等人,2018;Sap等人,2019;Davidson等人,2019;Hutchinson等人,2020),部分原因是对虚假特征的依赖,我们在第8节讨论。因此,我们在Amazon Mechanical Turk上对10K无毒子集中的120个随机提示进行了人工评估。对于每个提示,我们比较四对模型。DEXPERTS(large)与GPT-2 Large, PPLM, DAPT, and GeDi。对于每一对模型,我们从每个模型中随机抽取两代。这样一来,总共有个比较。
每一对对比都由三个Turkers评分,他们选择两个延续中的哪一个:(1)毒性更小,(2)更流畅,以及(3)更有主题,即延续内容是否自然、相关,以及是否符合提示的逻辑。Appendix C中提供了用户接口的截图。
Result:根据人类的评价,DEXPERTS被评为比所有基线的毒性更低(图2)。特别是,与GPT-2相比,它被评为同样流畅,但比GPT-2的毒性低的频率。各代的例子见Appendix E。
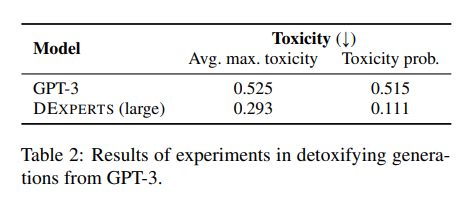
3.3 Steering GPT-3
我们接下来使用DEXPERTS来引导GPT-3 Ada。由于OpenAI的API只允许访问每个时间步骤的前100个对数概率,我们只能修改和取样前100个token的概率分布。尽管如此,表2中的结果显示,DEXPERTS有效地将GPT-3的毒性降低到与在GPT-2上操作时差不多的水平。这表明,DEXPERTS只需要基础模型的输出,事实上,(反)专家不需要建立在基础模型上。
3.4 Analysis: Dataset Size
在实践中,收集大量的有毒数据可能是一个挑战,特别是在我们想为有害语言的不同概念定制反专家LM的应用中。为了探索有限的数据设置,我们研究了用于训练(反)专家的数据集大小与它引导基础模型的有效性之间的关系。我们在五种不同的数据集规模上对GPT-2 Large进行了微调,这五种数据集规模分别为、、、和的标记;对于每种数据集规模,我们对专家和反专家进行一个历时的训练,每隔五分之一的历时就有一个检查点。图3显示了在每个(反)专家检查点的每个组合的性能。
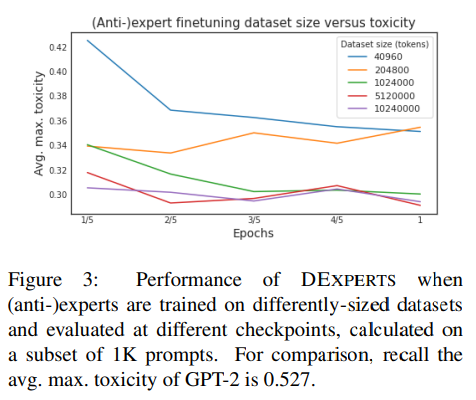
我们可以看到,即使有个tokens(条评论)的数据集,相当于原始毒性数据集的,我们也能从基础模型中大幅减少毒性,达到与我们最强基线GeDi相同的水平。(在一个GPU上,这相当于分钟的微调。)尽管如此,随着(反)专家的微调数据集的大小增加,DEXPERTS的性能也在增加。
4 Sentiment-Controlled Generation
作为第二种应用,我们考虑控制文本情感的极性这一经过深入研究的任务(例如,Li等人,2018;Sudhakar等人,2019),转向积极或消极的情感。
4.1 Method
我们使用第3节中相同的预训练模型GPT-2 Large作为我们的基础LM。我们在正面情绪语料库上对GPT-2(Small,Medium, Large)进行微调,并在负面情绪语料库上对我们的负面LM进行微调。我们使用斯坦福情感树库(SST-5;Socher等人,2013),其中包含由人类评分员标注的电影评论,其情感等级从1(非常消极)到5(非常积极)。我们的正面数据集包含 "正面 "和 "非常正面 "的评论,而我们的负面数据集包含 "负面 "或 "非常负面 "的评论。这些情感数据集中的每一个都有大约4K条评论。
为了便于记述,我们认为积极的LM我们的专家和消极的LM我们的反专家,并使用在每个方向的引导。的许多值的流畅性和情感控制之间的权衡在§4.3中显示。
4.2 Evaluation
4.2.1 Generation Prompts
为了测试我们的方法在情感专家被训练的领域(电影评论)之外控制情感的能力,我们从OpenWebText语料库(OWT)中收集了10万条自然发生的提示数据集(Gokaslan和Cohen,2019)。细节在Appendix B中概述。我们从基础LM中为每个提示生成25个延续,并使用HuggingFace的情感分析分类器(Wolf等人,2020)对SST-5电影评论进行训练,对它们进行评分。使用这些来自基础LM的生成,我们建立了三个提示的数据集。
- "中性 "提示,导致或个积极的延续
- "负面 "提示,导致个负面的延续
- "积极 "提示,导致或个积极的延续。我们认为消极和积极的提示是对抗性的,其任务是向提示的相反情绪引导。
4.2.2 Baselines
我们考虑了与第3节相同的基线,以及一个新的基线(CTRL;Keskar等人,2019)。
DAPT:与第3节中的DAPT基线相对应,我们用HuggingFace情感分类器对OpenWebText中的所有文档进行评分,并保留最积极的2%和最消极的2%(根据预测标签的概率),以获得积极和消极语料。我们对每个语料库进行另一轮预训练,以获得正向LM和负向LM。
PPLM:与毒性的第3条一样,我们重新训练了PPLM的情感分类器,其嵌入大小与我们的基础模型兼容。使用的训练数据是SST-5。同样,与其他模型相比,我们只在10%的提示语上评估PPLM,这些提示语是随机选择的。500个中性提示,250个正面提示,以及250个负面提示。
GeDi:我们使用GeDi和原作者发布的情感分类条件的LM,这些LM是在IMDB电影评论上训练的(Maas等人,2011)。(我们发现在SST-5上重新训练的结果是性能略有下降,如Appendix A所述)。
DEXPERTS (anti-only):为了探索简单地远离一种情绪是否会产生相反的情绪,我们再次探索DEXPERTS的纯反专家版本。和第3节一样,我们重新使用基础模型作为专家,并且只使用负面的反专家LM来进行正面引导,只使用正面的反专家LM来进行负面引导。我们在这个设置中使用。
Positive/Negative Experts:同样,我们考虑直接从相应的情感专家那里解码,进行正面和负面的引导。
Conditional Transformer LM (CTRL; Keskaret al., 2019):为了控制来自CTRL的生成的情绪,我们使用 "评论 "控制代码,为正面的各代人附加的评级,为负面的各代人附加的评级。CTRL的情感训练例子来自亚马逊的评论(McAuley等人,2015)。
与毒性实验(第3节)一样,我们使用nucleus抽样,,并在Appendix A中包括我们的训练和生成细节。
4.2.3 Automatic Evaluation
我们针对目标情感、流畅性和多样性来评估我们的生成。为了估计情感,我们使用HuggingFace的情感分析分类器,并报告每个提示中被标记为正面的生成(其余为负面)的平均百分比(共25个)。我们以与第3节相同的方式评估流畅性和多样性。
Results:如表3所示,DEXPERTS在中性提示和对抗性提示上都大大超过了以前的可控生成方法(PPLM, CTRL, DAPT, GeDi)。CTRL的有限表现表明,在特定领域的数据上进行类条件训练的有效性仅限于该数据的领域;在亚马逊评论上的训练不允许在评论领域之外进行概括。同样,虽然正面专家和负面专家取得了不错的表现(甚至在负面提示上表现最好),但他们是以更高的输出迷惑度为代价的。
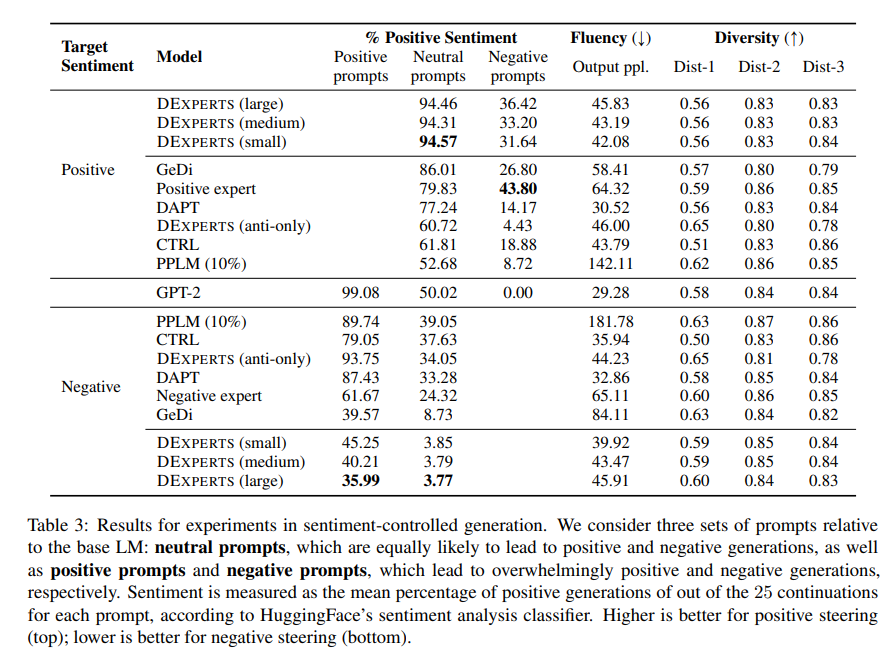
这种对比显示了同一个硬币的两面:我们观察到,虽然CTRL在域外提示上表现得像一个标准的语言模型(流畅性好,控制力差),但情感专家在电影评论上是高度专业化的,并倾向于将生成人导向电影(流畅性差,控制力强)。同时,DAPT在保持流畅性的同时更加有效,因为它的训练域与提示域相同(即OWT),但在需要更多主动引导的对抗性环境中,它的性能大幅下降。我们观察到,PPLM的流畅性差是由于偶尔有生成具有极高的困惑性,这表明有退化行为的情况。只有一个反专家的DEXPERTS在中性提示上是温和有效的(超过或匹配CTRL和PPLM的性能),但在对抗性设置中效果很差,证实了我们的直觉,即引导远离负面情绪并不能为正面情绪提供足够强大的指导。
4.2.4 Human Evaluation
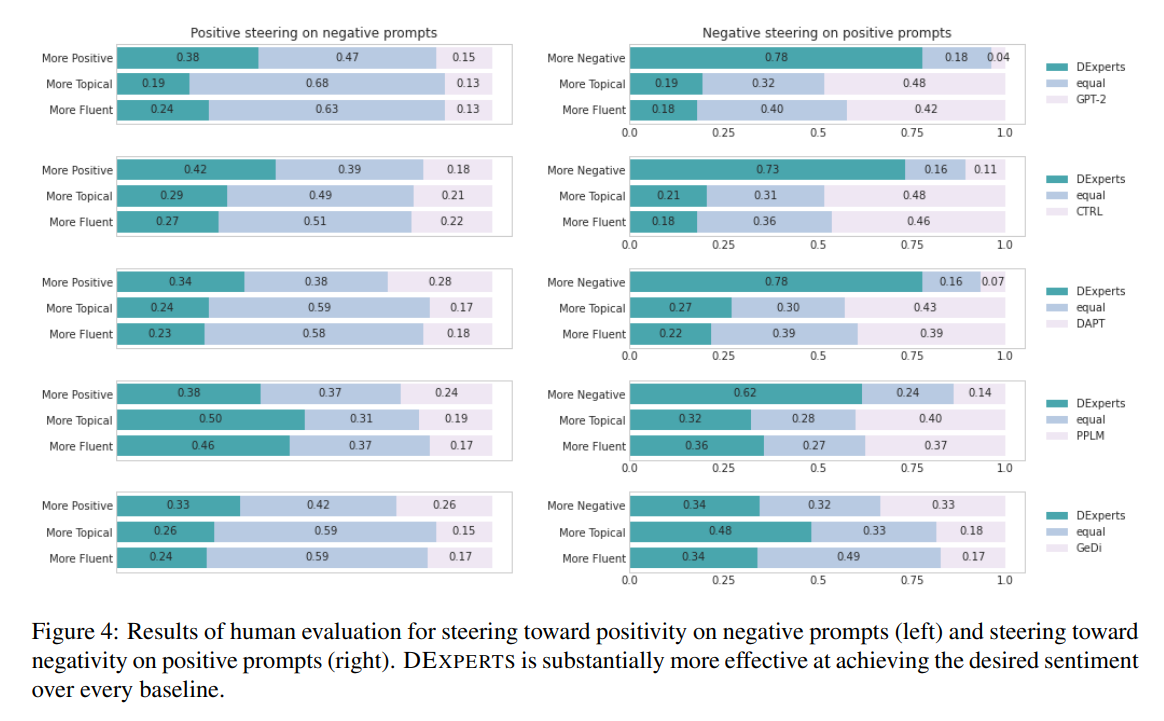
对于人类的评价,我们随机选择了30个中性提示、30个正面提示和30个负面提示,并考虑了五对模型。DEXPERTS与GPT-2、CTRL、PPLM、DAPT和GeDi。对于每个提示和配对的模型,我们从每个模型的每个引导方向上抽出两个生成。这导致总共有,每个配对由3个MTurk工作者评定。我们要求注释者选择哪一代能更好地实现所需的情感,以及§3.2.4中的流畅性和主题性问题。
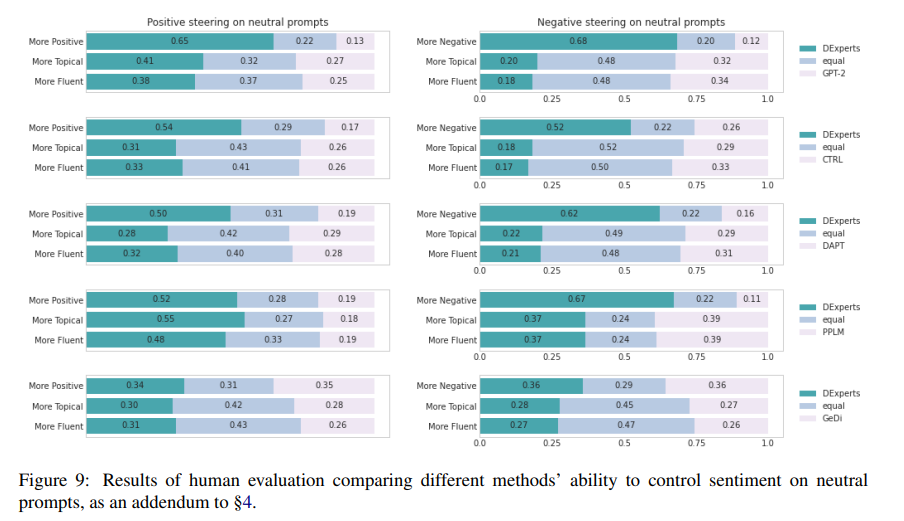
Results:如图4所示,与包括GPT-2在内的所有其他基线相比,DEXPERTS在引导负面提示的积极性方面明显更有效,同时实现了更好的主题性和更好的流畅性。在对正面提示进行负面引导的相反情况下,在DEXPERTS与GPT-2、CTRL、DAPT和PPLM之间在情感控制方面的差距甚至更加明显。DEXPERTS在62-78%的时间里被评为优于其比较对象。虽然GeDi在这种情况下取得了接近DEXPERTS的表现,但其主题性和流畅性却差得多。这种不对称性,即DEXPERTS的负向引导似乎比正向引导更容易,也反映在自动评估中。我们假设,用消极的东西破坏积极的提示比把消极的东西变成积极的东西更容易;但对人类读者来说,这些消极的延续可能是意想不到的(以前的工作中也有类似的观察;Madotto等人,2020)。对于中性提示,我们看到类似于自动和人类对抗性评价的趋势。由于篇幅限制,我们将这些内容列入Appendix D.2。
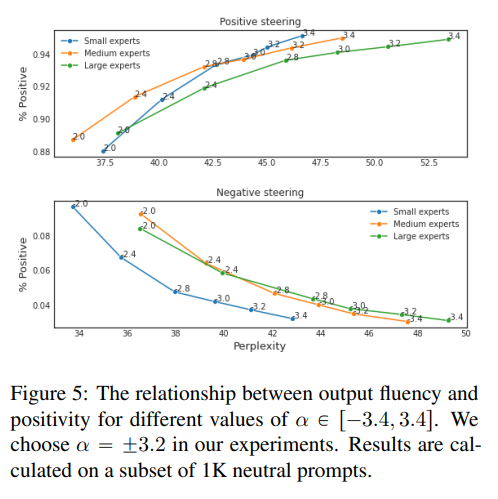
4.3 Analysis: Sentiment versus Fluency
在实践中,我们可能希望根据不同的应用来进行不同程度的情感控制(例如,积极的营销宣传与仅仅是友好的聊天机器人)。图5显示了在中性提示的条件下,不同的的选择,输出情感和流畅性之间的关系。平稳的权衡表明,可以由从业者或用户根据他们的应用来调整。在我们的实验中,我们选择,因为曲线变得不那么陡峭,这意味着在流畅性方面的更大的成本不会在所需的情感中得到那么大的增长。对于DEXPERTS解毒来说,输出毒性和流畅性之间的权衡看起来非常相似(§3),并包含在附录D.1中。
5 Stylistic Rewriting with DEXPERTS
作为初步探索,我们超越了生成文本的连续性,将DEXPERTS应用于分风格迁移,即在尽可能保留内容的情况下以目标风格迁移一个句子。我们用一个预训练的自动编码器BART(Lewis等人,2020)取代基础模型,并使用第4节中的GPT-2大型情感(反)专家进行引导。在每个时间步骤中,自动编码器基础模型以输入序列和迄今为止的生成为条件,而(反)专家只以后者为条件。作为概念的证明,我们在表4中展示了这个系统的一些输入/输出的例子。
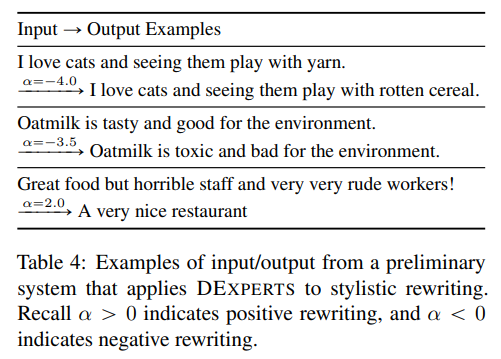
这一探索表明,将DEXPERTS应用于风格迁移需要更多的创新,但这是一个很有前景的方向。我们期待着未来在这个问题上的工作。
6 Related Work
控制语言生成模型的输出的任务已经被以前的工作广泛研究(关于回顾,见Prabhumoye等人,2020)。在使用预训练的LM作为骨干之前,大多数工作都使用了为各自的下游生成任务训练的定制神经模型,包括情感感知的文本生成(Ghosh等人,2017;Ficler和Goldberg,2017),属性感知的产品评论生成(Dong等人,2017),以及友好或同情的对话响应生成(See等人,2019;Rashkin等人,2019)。
由于预训练的LM已经显示出令人印象深刻的文本生成能力(Radford等人,2018,2019),出现了两个方向来控制其语言生成:训练方法和解码时间方法。训练方法包括在包含所需属性的数据集上对预训练的LM进行微调(Gururangan等人,2020),以及创建一个在具有特定属性控制代码前缀的文本上训练的类条件预训练LM(Keskar等人,2019)。与我们的方法相比,这些方法只能引导到所需的文本属性,它们不能引导到远离它们。此外,训练方法需要大量的计算资源,随着最近的预训练LM的规模,这可能不再可行(Brown等人,2020;Fedus等人,2021)。
解码时间方法是一种更轻的方法,已被用于控制生成文本的属性,以及用于提高其质量(Li等人,2016;Holtzman等人,2018;Welleck等人,2020)。PPLM(Dathathri等人,2020)是一种转向方法,根据分类器对所需类别的梯度,更新预训练模型的隐藏表征。不幸的是,这种方法的计算成本很高,正如这项工作和以前的工作(Gehman等人,2020年)所示。与我们的工作同时,FUDGE(Yang和Klein,2021)在部分序列上训练分类器,以预测一个属性在未来是否会被满足,并使用贝叶斯分解法来获得属性条件的概率分布。GeDi(Krause等人,2020)类似地使用贝叶斯法则,但使用类条件的LM的输出来计算分类概率,而不是直接训练分类器。相比之下,我们的实验表明,直接集合LM的概率,而不是用它们来估计类的概率,对引导文本生成更有效。
7 Conclusion
我们提出了DEXPERTS,一种用于控制文本生成的方法,它根据专家(和反专家)的意见对语言模型的预测进行重新加权。在两个不同的任务(解毒和情绪控制)的实验中,我们表明我们的方法能够有效地引导语言模型走向所需的生成,同时保持生成文本的流畅性和多样性。随着建立在语言模型上的应用变得无处不在,DEXPERTS展示了引导这些模型走向安全和用户友好的生成的前景。
8 Broader Impact and Ethical Implications
我们的研究是由使用预训练的语言模型的潜在危害所激发的(Bender等人,2021),特别是他们产生仇恨、攻击性或有毒内容的倾向(Sheng等人,2020;Gehman等人,2020)。我们的部分工作需要在生成的文本中自动检测毒性,为此我们使用了Perspective API.7这个商业化部署的毒性检测工具。然而,毒性的构造和它通过自动分类器的操作化之间的不匹配会导致有偏见的或非预期的模型行为(Jacobs 和 Wallach,2021)。具体来说,最近的工作表明,这种仇恨言论分类器高估了包含少数民族身份提及的文本(Hutchinson等人,2020年;Dixon等人,2018年)或由少数民族撰写的文本(Sap等人,2019年;Davidson等人,2019年)中毒性的普遍性,因此确实有可能违背其公平和包容性对话的目的。为了解决这一局限性,我们还对毒性进行了人工评估。
我们也承认,任何可控的解毒方法都有双重用途的风险(Pandya,2019),具体来说,这项技术可以用来自动生成仇恨性文本(例如,极端主义文本;McGuffie和Newhouse,2020)。关于此类风险以及一般大型预训练LM的风险的更广泛讨论,请参见Bender等人(2021)。
尽管如此,预训练的LM中的毒性是一个未解决的问题(Sheng等人,2019;Gehman等人,2020)。因此,我们希望未来的工作继续更好地定义和评估有害语言的存在(例如,Sap等人,2020年),并开发减轻这种语言的系统,可以根据用户的不同语言经验进行个性化处理(例如,适当处理回收的污辱;Croom,2013)。
Appendix Overview
在这份补充材料中,我们提供了产生论文结果的额外信息和额外结果。
A.1 Out of the Box Models
我们使用HuggingFace Transformers(Wolf等人,2020)版本的所有预训练模型(除GPT-3外),在PyTorch深度学习框架中实现。对于GPT-3,我们使用Ada模型,该模型可通过OpenAI API访问。
A.2 Training Details
所有的训练都是在单个NVIDIA Quadro 6000 GPU上进行的。
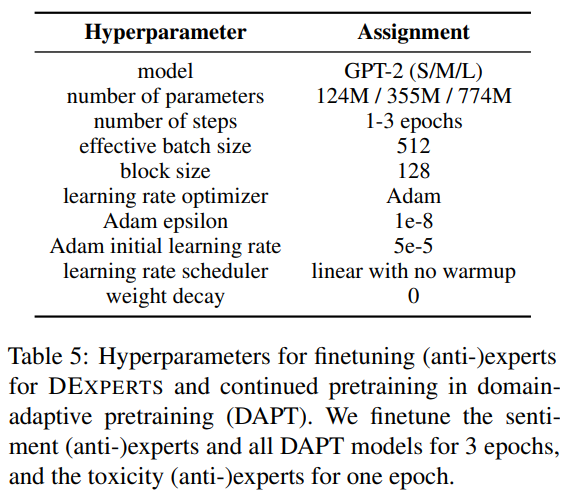
DEXPERTS:表5给出了用于对DEXPERTS的(反)专家进行微调的超参数。
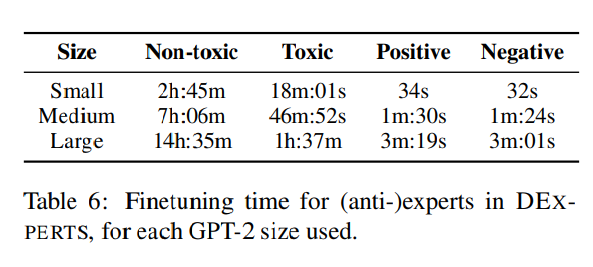
每个模型大小的微调时间见表6。
DAPT:对于我们在情感实验中的DAPT实现(第4节),我们使用HuggingFace的情感分析分类器来过滤OpenWebText()中最积极的2%和最消极的2%的文档。因为该分类器最多使用512个标记作为输入文本,所以我们用文档的前510个标记(分类器会添加一个开始和结束标记)来近似判断文档的情绪。表5中给出了在属性数据上进行预训练的额外阶段的超参数。
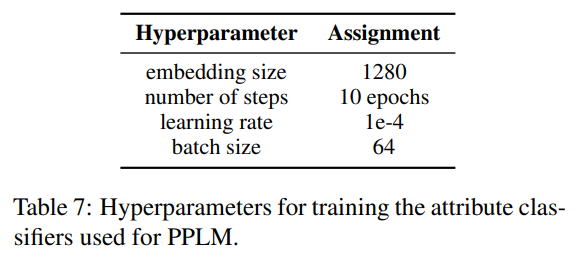
PPLM:对于我们在实验中对PPLM的实现,我们重新训练了毒性和情感分类器,使其与我们的基础模型GPT-2(大)兼容,因为原论文使用GPT-2中进行实验。我们使用与原PPLM论文中相同的训练数据集和超参数。
GeDi:对于毒性和情感的引导,我们下载了原作者提供的类条件语言模型(基于GPT-2中)。作为实验,我们还通过对SST-5数据(而不是GeDi中使用的IMDB)进行微调,使情感GeDis和DEXPERTS中使用的(反)专家的微调数据一致。我们发现在不同的设置中,情感控制的性能略低("1-2%"),因此使用了原始的类条件LMs。
A.3 Dataset Details
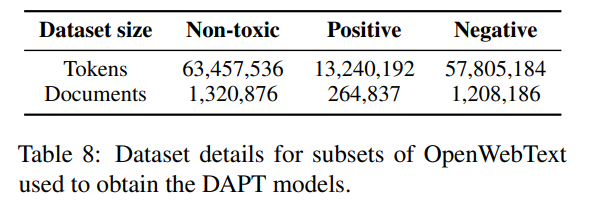
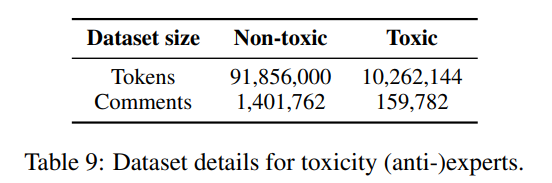
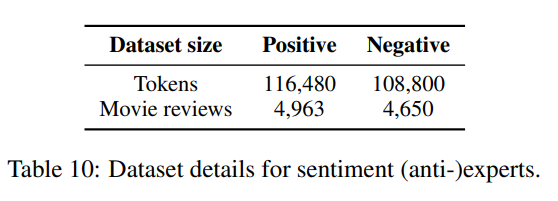
表8给出了用于DAPT基线进一步预训练的数据集的细节,表9和表10给出了用于微调我们的专家和反专家的数据。
A.4 Generation Details
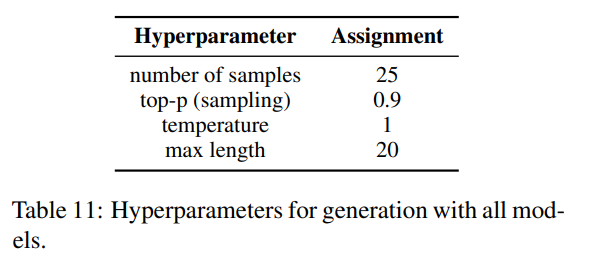
所有方法共享的生成超参数如表11所示。PPLM生成的超参数如表12所示。根据作者的建议,我们在20个无毒提示的小样本上对步长,以及迭代次数进行了超参数搜索。我们选择了步长和次迭代,以获得毒性降低和输出流畅性之间的最佳权衡。由于这种方法的计算费用极高,我们无法对情感提示重复进行超参数搜索。

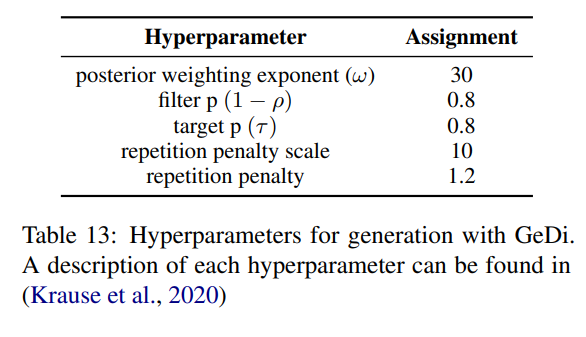
我们在表14中比较了§3中使用的每种可控生成方法的运行时间,所有这些都是在一个NVIDIA Quadro 6000 GPU上进行的。我们看到,DEXPERTS需要的时间是直接从基础模型解码的2到3倍,这取决于(反)专家的大小。当使用与GeDi相同的指导语言模型规模时(GPT-2中),DEXPERTS比GeDi更有效率,两种方法都比PPLM快。
B Collection of Sentiment Prompts
我们从OpenWebText语料库(Gokaslan和Cohen,2019)中建立我们的情感实验提示(第4节),这是一个从Reddit上的外链中刮出的英语网络文本语料库。我们从OpenWebText中随机抽取10万个文档,并将每个文档标记为句子。按照RealToxicityPrompts(Gehman等人,2020)的创建方法,我们将每个句子分成由前半部分标记组成的提示和由其余标记组成的续篇。我们只保留长度在4到10个令牌之间的提示语(包括)。对于所有的标记化,我们使用NLTK库(Bird和Loper,2004)。这导致了1.4亿条提示语,我们从中随机抽出10万条提示语。
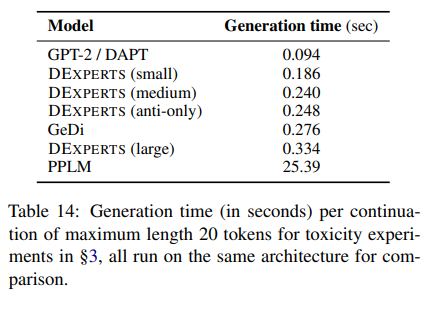
对于10万条提示中的每一条,我们从我们的基础模型GPT-2(大)中生成25个连续句,并使用§4中描述的HuggingFace情感分类器对这些连续句进行情感评分。图6显示了在25个提示中具有积极延续的提示的分布。有趣的是,我们观察到更多的提示语的负面延续比正面延续多,反之亦然。基于这些世代,我们创建了三套提示语,如第4节所述
C Human Evaluation
我们用于人类评价的界面如图7所示。对于每个类别,注释者可以选择其中的一个延续,或者将两个选项评为相等。

D Additional Results
D.1 Toxicity Hyperparameter Control
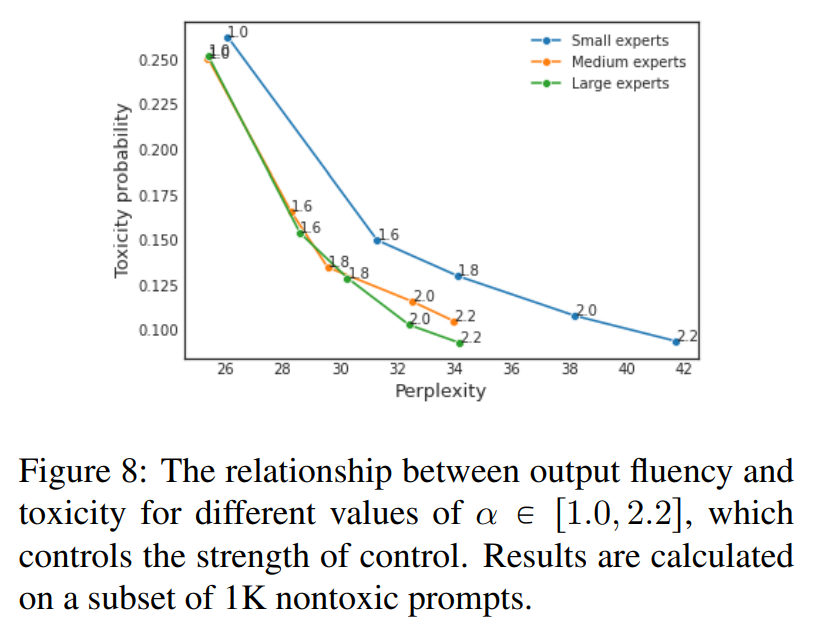
图8显示了在我们的方法中,不同的值下输出的毒性和流畅性之间的关系。这种关系是平滑的,反映了§4.3中关于情感的相应数字。
D.2 Human Evaluation on Neutral Prompts
图9显示了人类对以中性提示为条件的情感控制的评价结果。
E Generation Examples
表15给出了每种方法的生成实例,用于解毒(§3),表16用于情绪控制(§4)。

