论文名称 Controllable Text Generation with Neurally-Decomposed Oracleopen in new window
会议: NIPS2022
Abstract 我们提出了一个通用的、高效的框架,用NeurAlly-Decomposed Oracle(NADO)控制自动回归生成模型。给定一个预先训练好的基础语言模型和一个序列级的布尔oracle函数,我们建议将oracle函数分解为token级的指导,以引导文本生成中的基础模型。具体来说,token级引导由一个用基础模型采样的例子训练的神经模型来近似,不需要额外的辅助标记数据。我们提出了封闭式的最佳解决方案,将token级引导纳入可控生成的基础模型。我们进一步提供了关于NADO的近似质量如何影响可控生成结果的理论分析。在两个应用中进行的实验:(1)带有词汇约束的文本生成和(2)带有形式控制的机器翻译,表明我们的框架能有效地引导基础模型向给定的oracle前进,同时保持高的生成质量。
1 Introduction 自动回归语言模型已被广泛用于文本生成。随着最近大规模预训练语言模型的发展Radford等人(2019);Brown等人(2020);Raffel等人(2020);Lewis等人(2020),他们在机器翻译(Bahdanau等人。2015;Luong等人,2015)、图像字幕(Anderson等人,2018;You等人,2016)和开放域文本生成(Zhang和Lapata,2014;Yao等人,2019;Vinyals和Le,2015;Shang等人,2015;Lu等人,2018)。然而,许多应用需要用特定的序列级属性来控制模型输出。这些属性可以由一组规则或一个抽象的概念(例如,生成的文本遵循特定的写作风格)来指定。如何控制自动回归语言模型以满足这些属性是一个公开的挑战。
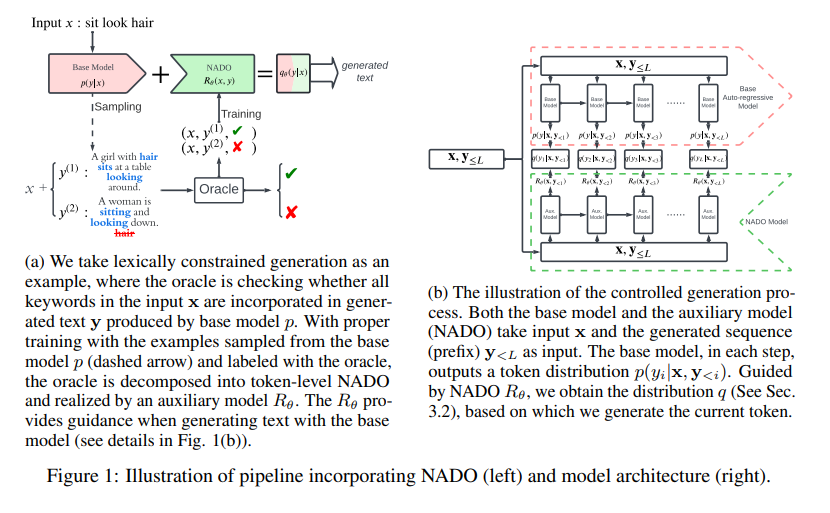
在本文中,我们提出了一个通用的、灵活的可控生成框架。给定一个基础的预训练语言模型和一个表明是否满足某个属性的序列级oracle函数,我们的目标是通过神谕引导文本生成以满足某些属性。为此,我们建议将序列级属性分解为token级引导。当在输出序列中生成第i个标记时,我们不是从给定前缀的基础模型中取样,而是根据token级引导来修改输出标记的概率分布。具体来说,我们将控制制定为一个基于后验正则化的优化问题(Ganchev等人,2010),并解决近似形式的最优解,以纳入文本生成的token级指导。分解由一个辅助的神经网络模型近似,称为NeurAlly-Decomposed Oracle(NADO),它是在从基础模型采样的数据上训练的,并由序列级神谕监督(见图1a的说明)。我们进一步提供理论分析,说明NADO的近似质量如何影响可控的生成结果。请注意,在整个过程中,我们把基础模型和序列级oracle作为黑箱函数,不需要任何重构或微调。
现有的一些可控生成工作(例如Lu等人(2021))为词汇约束设计了解码算法。然而,他们的方法是纯算法的,一般不能应用于其他类型的口令。另一线工作,如PPLM(Dathathri等人,2020)、GeDI(Krause等人,2021)和FUDGE(Yang和Klein,2021)也旨在用一个辅助模型来指导基础模型。然而,它们要么以一种事后的方式改变基础模型的分布,而没有理论上的保证,要么/和需要外部标记的数据来训练辅助模型。相反,我们为纳入oracle的最佳方式推导出一个闭合式的解决方案,而不需要外部标记数据或标记级指导。此外,由于NADO是在基础模型采样的数据上训练的,所以它与基础模型的一致性更好,从而可以实现更好的控制。
我们对词汇约束生成(LCG)任务和机器翻译(MT)形式变化任务进行了实验。在LCG任务中,oracle是一个基于规则的关键词检查器。与之前设计特定解码算法的方法相比,我们实现了几乎完美的关键词整合,并大大提升了BLEU分数。在形式控制的MT任务中,我们提供了一个形式oracle,预测一个句子是否是正式的,目标是引导模型产生正式的翻译。与最近的工作Yang和Klein(2021)相比,我们将BLEU得分提高了3分,并提高了形式化率,证明了NADO在纳入外部oracle监督方面的卓越能力。两个实验都证明了我们的框架在处理各种类型的控制和生成高质量文本方面的有效性。
Controllable Text Generation with Auto-regressive Models :以前大多数关于可控文本生成的工作都是基于自动回归框架的。Zhang等人(2022)将这些方法总结为三类:微调、重构/再训练和后处理。前两类,如CTRL(Keskar等人,2019)、提示方法(Shin等人,2020;Lester等人,2021;Li和Liang,2021),考虑到现在语言模型的规模正在急剧增加,通常控制力较弱,训练效率低下。一般来说,后处理方法被认为在推理方面很昂贵,而且生成的文本质量低。然而,我们的框架,作为一种后处理方法,能够实现实验中所证明的高生成质量,并且在推理时间上是高效的。
Controllable Text Generation via Post-processing :后处理有两条主线:(1)适应解码算法;(2)用辅助模型指导生成。对于一些token级控制的生成任务,如词汇约束生成,我们可以将约束注入到解码算法中(例如,约束束搜索(Anderson等人,2017)和NeuroLogic解码(Lu等人,2021))。虽然在词汇约束生成中显示出了有效性,但这些算法方法未能从根本上触及标记分布,也很难处理其他抽象属性。
在第二条线上,PPLM(Dathathri等人,2020)提出了一个用于指导模型的预期属性的辅助判别器;GeDi(Krause等人,2021)和DEXPERTS(Liu等人,2021)应用对比学习,训练一个辅助语言模型,在每个步骤中重新加权标记分布;Plug-and-Blend(Lin和Riedl,2021)通过添加一个规划器架构进一步扩展了GeDi框架。FUDGE(Yang和Klein,2021)利用外部token级oracle来训练一个用于指导基础模型的判别器。这些方法要么需要外部token级oracle指导,要么需要辅助标记的数据集来训练辅助模型。然而,用于训练辅助模型的数据的分布与基础模型的训练是不同的。这种分布上的差异导致了生成质量的下降,我们将在实验中展示。例如,给定一个控制属性a,Fudge根据贝叶斯规则P ( y i ∣ y < i , a ) ∝ P ( a ∣ y ≤ i ) P ( y i ∣ y < i ) P(y_i|\textbf{y}_{<i},a)\propto P(a|\textbf{y}\leq i)P(y_{i}|\textbf{y}_{<i}) P ( y i ∣ y < i , a ) ∝ P ( a ∣ y ≤ i ) P ( y i ∣ y < i ) y i y_i y i P ( a ∣ y ≤ i ) P(a|\textbf{y}\leq i) P ( a ∣ y ≤ i ) P ( y i ∣ y < i ) P(y_i|\textbf{y}_{<i}) P ( y i ∣ y < i )
3.Methodology 我们通过将句子级oracle分解为token级引导来处理序列级可控生成问题。我们将其表述为一个优化问题。由于token级指导是难以解决的,我们建议训练一个辅助模型,称为神经分解oracle(NADO),以近似它。在推理过程中,NADO指导基础模型生成满足oracle约束的序列。
在本节的其余部分,我们将讨论:
1)将序列级oracle函数分解为token级引导的表述。 2)将token级引导纳入基础模型以实现控制的表述。 3)使用NADO对token级引导进行近似。 4)从理论上分析NADO近似对可控生成结果的影响。 5)NADO的训练。 我们用x ∈ X \textbf{x}{\in}\mathcal{X} x ∈ X y ∈ Y \textbf{y}{\in}\mathcal{Y} y ∈ Y y i y_i y i y \textbf{y} y i i i y < i \textbf{y}_{<i} y < i ( i − 1 ) (i-1) ( i − 1 ) p ( y i ∣ x , y < i ) p(y_i |\textbf{x},\textbf{y}_{<i}) p ( y i ∣ x , y < i ) p ( y ∣ x ) = ∏ i p ( y i ∣ x , y < i ) p(\textbf{y}|\textbf{x})=\prod_{i}p(y_i|\textbf{x},\textbf{y}_{<i}) p ( y ∣ x ) = ∏ i p ( y i ∣ x , y < i ) C : X × Y → { 0 , 1 } C:\mathcal{X}{\times}\mathcal{Y}{\rightarrow}\{0,1\} C : X × Y → { 0 , 1 } q ∗ ( y i ∣ x , y < i ) q^*(y_i|\textbf{x},\textbf{y}_{<i}) q ∗ ( y i ∣ x , y < i ) q ∗ ( y ∣ x ) q^*(\textbf{y}|\textbf{x}) q ∗ ( y ∣ x )
q ∗ ( y ∣ x ) = ∏ i q ∗ ( y i ∣ x , y < i ) q^*(\textbf{y}|\textbf{x})=\prod_i q^*(y_i|\textbf{x},\textbf{y}_{<i}) q ∗ ( y ∣ x ) = ∏ i q ∗ ( y i ∣ x , y < i ) q ∗ q^* q ∗ q ∗ ( y ∣ x ) = 0 if C ( x , y ) = 0 q^*(\textbf{y}|\textbf{x})=0 \ \text{if}\ C(\textbf{x},\textbf{y})=0 q ∗ ( y ∣ x ) = 0 if C ( x , y ) = 0 q ∗ q^* q ∗ C C C 给定一个输入x \textbf{x} x KL ( p ( y ∣ x ) ∣ ∣ q ∗ ( y ∣ x ) ) \text{KL}(p(\textbf{y}|\textbf{x})||q^*(\textbf{y}|\textbf{x})) KL ( p ( y ∣ x ) ∣∣ q ∗ ( y ∣ x )) q ∗ q^* q ∗ 在我们计算q ∗ q^∗ q ∗ p p p C C C R p C ( x ) R_p^C(\textbf{x}) R p C ( x ) p p p x \textbf{x} x R p C ( x , y < i ) R^C_p(\textbf{x},\textbf{y}_{<i}) R p C ( x , y < i ) x \textbf{x} x y < i \textbf{y}_{<i} y < i
R p C ( x ) = Pr y ∼ p ( y ∣ x ) [ C ( x , y ) = 1 ] = ∑ y ∈ Y p ( y ∣ x ) C ( x , y ) R p C ( x , y < i ) = Pr y ∼ p ( y ∣ x ) [ C ( x , y ) = 1 ∣ y < i ] = ∑ y ∈ Y p ( y ∣ y < i ) C ( x , y ) \begin{equation} \begin{aligned} R_p^C(\textbf{x})=\text{Pr}_{\textbf{y}\sim p(\textbf{y}|\textbf{x})}[C(\textbf{x},\textbf{y})=1]=\sum_{\textbf{y}{\in}\mathcal{Y}}p(\textbf{y}|\textbf{x})C(\textbf{x},\textbf{y})\\ R_p^C(\textbf{x},\textbf{y}_{<i})=\text{Pr}_{\textbf{y}\sim p(\textbf{y}|\textbf{x})}[C(\textbf{x},\textbf{y})=1|\textbf{y}_{<i}]=\sum_{\textbf{y}{\in}\mathcal{Y}}p(\textbf{y}|\textbf{y}_{<i})C(\textbf{x},\textbf{y}) \end{aligned} \end{equation} R p C ( x ) = Pr y ∼ p ( y ∣ x ) [ C ( x , y ) = 1 ] = y ∈ Y ∑ p ( y ∣ x ) C ( x , y ) R p C ( x , y < i ) = Pr y ∼ p ( y ∣ x ) [ C ( x , y ) = 1∣ y < i ] = y ∈ Y ∑ p ( y ∣ y < i ) C ( x , y )
有了函数R p C R^{C}_{p} R p C q ∗ q^* q ∗ x \textbf{x} x Q Q Q
Q ≔ { q ∣ ∑ q : C ( x , y ) q ( y ∣ x ) = 0 } \begin{equation} \begin{aligned} Q\coloneqq\{q|\sum_{\textbf{q}:C(\textbf{x},\textbf{y})}q(\textbf{y}|\textbf{x})=0\} \end{aligned} \end{equation} Q : = { q ∣ q : C ( x , y ) ∑ q ( y ∣ x ) = 0 }
那么q ∗ q^* q ∗
q ∗ ( y ∣ x ) = arg min q ∈ Q KL ( p ( y ∣ x ) ∣ ∣ q ( y ∣ x ) ) = p ( y ∣ x ) C ( x , y ) R p C ( X ) \begin{equation} \begin{aligned} q^*(\textbf{y}|\textbf{x})=\mathop{\arg\min}_{q{\in Q}}\text{KL}(p(\textbf{y}|\textbf{x})||q(\textbf{y}|\textbf{x}))=\frac{p(\textbf{y}|\textbf{x})C(\textbf{x},\textbf{y})}{R_{p}^{C}(\textbf{X})} \end{aligned} \end{equation} q ∗ ( y ∣ x ) = arg min q ∈ Q KL ( p ( y ∣ x ) ∣∣ q ( y ∣ x )) = R p C ( X ) p ( y ∣ x ) C ( x , y )
考虑到条件(1)并使q ∗ q^∗ q ∗ q ∗ ( y ∣ x ) q^*(\textbf{y}|\textbf{x}) q ∗ ( y ∣ x )
q ∗ ( y i ∣ x , y < i ) = R p C ( x , y < i ) R p C ( x , y < i − 1 ) p ( y i ∣ x , y < i ) \begin{equation} \begin{aligned} q^*(y_i|\textbf{x},\textbf{y}_{<i})=\frac{R^C_p(\textbf{x},\textbf{y}_{<i})}{R_{p}^C(\textbf{x},\textbf{y}_{<i-1})}p(y_i|\textbf{x},\textbf{y}_{<i}) \end{aligned} \end{equation} q ∗ ( y i ∣ x , y < i ) = R p C ( x , y < i − 1 ) R p C ( x , y < i ) p ( y i ∣ x , y < i )
分解是唯一的。证明和详细推导可在附录中找到。
Control with Soft Constraints :在公式(2)中,我们将可行的分布集定义为序列违反oracle函数的可能性为0的分布。然而,在某些应用中,我们希望用软约束来控制生成。例如,我们希望该模型能以r = 0.8 r=0.8 r = 0.8 r ∈ [ 0 , 1 ] r{\in}[0,1] r ∈ [ 0 , 1 ] Q Q Q
Q ≔ { q ∣ ∑ q : C ( x , y ) q ( y ∣ x ) = r } \begin{equation} \begin{aligned} Q\coloneqq\{q|\sum_{\textbf{q}:C(\textbf{x},\textbf{y})}q(\textbf{y}|\textbf{x})=r\} \end{aligned} \end{equation} Q : = { q ∣ q : C ( x , y ) ∑ q ( y ∣ x ) = r }
其中,公式(2)是r = 0 r=0 r = 0
q ∗ ( y i ∣ x , y < i ) = α R p C ( x , y < i ) + β ( 1 − R p C ( x , y < i ) ) α R p C ( x , y < i − 1 ) + β ( 1 − R p C ( x , y < i − 1 ) ) p ( y i ∣ x , y < i ) \begin{aligned} q^*(y_i|\textbf{x},\textbf{y}_{<i})=\frac{\alpha R^{C}_{p}(\textbf{x},\textbf{y}_{<i})+\beta(1-R^C_p(\textbf{x},\textbf{y}_{<i}))}{\alpha R^{C}_{p}(\textbf{x},\textbf{y}_{<i-1})+\beta(1-R^C_p(\textbf{x},\textbf{y}_{<i-1}))}p(y_i|\textbf{x},\textbf{y}_{<i}) \end{aligned} q ∗ ( y i ∣ x , y < i ) = α R p C ( x , y < i − 1 ) + β ( 1 − R p C ( x , y < i − 1 )) α R p C ( x , y < i ) + β ( 1 − R p C ( x , y < i )) p ( y i ∣ x , y < i )
其中α = r R p C ( x ) \alpha=\frac{r}{R^C_p(\textbf{x})} α = R p C ( x ) r β = 1 − r 1 − R p C ( x ) \beta=\frac{1-r}{1-R_p^{C}(\textbf{x})} β = 1 − R p C ( x ) 1 − r
与公式(4)类似,一旦我们获得了R p C R^C_p R p C r = 0 r=0 r = 0
3.3 Approximating R p C R_p^C R p C 不幸的是,公式(1)中定义的函数R p C R^C_p R p C R θ R_\theta R θ θ \theta θ R θ R_\theta R θ R p C R_p^C R p C
Lemma1 : 我们定义分布
q ( y i ∣ x , y < i ) ∝ R θ ( x , y < i ) R θ ( x , y i − 1 ) p ( y i ∣ x , y < i ) . \begin{equation} \begin{aligned} q(y_i|\textbf{x},\textbf{y}_{<i}) \propto \frac{R_{\theta}(\textbf{x},\textbf{y}_{<i})}{R_\theta(\textbf{x},\textbf{y}_{i-1})}p(y_i|\textbf{x},\textbf{y}_{<i}). \end{aligned} \end{equation} q ( y i ∣ x , y < i ) ∝ R θ ( x , y i − 1 ) R θ ( x , y < i ) p ( y i ∣ x , y < i ) .
如果存在δ > 1 \delta>1 δ > 1 x , ∀ y < i , 1 δ < R θ ( x , y < i ) R p C ( x , y < i > ) < δ \textbf{x},\forall\textbf{y}_{<i},\frac{1}{\delta}<\frac{R_\theta(\textbf{x},\textbf{y}_{<i})}{R_p^C(\textbf{x},\textbf{y}_{<i>})}<\delta x , ∀ y < i , δ 1 < R p C ( x , y < i > ) R θ ( x , y < i ) < δ
KL ( q ∗ ( y ∣ x ) ∣ ∣ q ( y , x ) ) < ( 2 L + 2 ) ln δ \begin{aligned} \text{KL}(q^*(\textbf{y}|\textbf{x})||q(\textbf{y},\textbf{x}))<(2L+2)\ln\delta \end{aligned} KL ( q ∗ ( y ∣ x ) ∣∣ q ( y , x )) < ( 2 L + 2 ) ln δ
如果R也满足公式(6),我们可以收紧这个约束。从形式上看,
Lemma2 :鉴于lemma1中的条件,如果q q q ∑ y i R θ ( x , y < i ) R θ ( x , y i − 1 ) p ( y i ∣ x , y < i ) = 1 \sum_{y_i}\frac{R_{\theta}(\textbf{x},\textbf{y}_{<i})}{R_\theta(\textbf{x},\textbf{y}_{i-1})}p(y_i|\textbf{x},\textbf{y}_{<i})=1 ∑ y i R θ ( x , y i − 1 ) R θ ( x , y < i ) p ( y i ∣ x , y < i ) = 1
∀ x , KL ( q ∗ ( y ∣ x ) ∣ ∣ q ( y , x ) ) < 2 ln δ \begin{aligned} \forall\ x,\text{KL}(q^*(\textbf{y}|\textbf{x})||q(\textbf{y},\textbf{x}))<2\ln\delta \end{aligned} ∀ x , KL ( q ∗ ( y ∣ x ) ∣∣ q ( y , x )) < 2 ln δ
这个定理表明,在自动回归特性下,误差不会随着序列的变化而累积。证明在附录中。这两个界限表明,在模型R R R R θ R_\theta R θ R p C R_p^C R p C
3.4 Training NADO 在图1b中,我们展示了NADO的结构。一般来说,NADO可以是任何seq2seq模型。在训练中,它把x , y \textbf{x},\textbf{y} x , y R θ ( x , y < 0 ) R_\theta(\textbf{x},\textbf{y}_{<0}) R θ ( x , y < 0 ) R θ ( x , y < T ) R_\theta(\textbf{x},\textbf{y}_{<T}) R θ ( x , y < T ) R θ R_\theta R θ R θ ( x , y < i ⨁ y ) R_\theta(\textbf{x},\textbf{y}_{<i} \bigoplus y) R θ ( x , y < i ⨁ y ) y y y ⨁ \bigoplus ⨁ R θ R_\theta R θ p p p q q q 2 × 2{\times} 2 ×
3.5 Sampling 在第3.4节中,我们描述了我们通过对基础模型p p p R θ R_\theta R θ
Sampling with Temperature Control :在一些任务中,输出序列的变化不大,换句话说,每一步的标记分布是非常峰值的。由于我们的NADO是在抽样的例子上训练的,我们希望这些例子尽可能多地覆盖标记组合,以避免过度拟合。因此,我们添加温度系数T T T p ( y ∣ x ) 1 T p(\textbf{y}|\textbf{x})^{\frac{1}{T}} p ( y ∣ x ) T 1 y \textbf{y} y p ( y ∣ x ) 1 − 1 T p(\textbf{y}|\textbf{x})^{1-\frac{1}{T}} p ( y ∣ x ) 1 − T 1
E y ∼ p ( t e x t b f y ∣ x ) 1 T = [ p ( y ∣ x ) 1 − 1 T L C E ( x , y , R θ ) ] = ∑ y ∈ Y p ( y ∣ x ) L C E ( x , y , R θ ) \begin{aligned} \mathbb{E}_{\textbf{y}\sim p(textbf{y}|\textbf{x})^{\frac{1}{T}}}=[p(\textbf{y}|\textbf{x})^{1-\frac{1}{T}L_{CE}(\textbf{x},\textbf{y},R_{\theta})}]=\sum_{\textbf{y}{\in}\mathcal{Y}}p(\textbf{y}|\textbf{x})L_{CE}(\textbf{x},\textbf{y},R_{\theta}) \end{aligned} E y ∼ p ( t e x t b f y ∣ x ) T 1 = [ p ( y ∣ x ) 1 − T 1 L CE ( x , y , R θ ) ] = y ∈ Y ∑ p ( y ∣ x ) L CE ( x , y , R θ )
这与公式(7)中的原始预期损失相同。
Importance Sampling :在实践中,当基础模型p p p C C C E y ∼ p ( y ∣ x ) [ p ( C ∣ x , y ) ] ≃ 0 \mathbb{E}_{\textbf{y}\sim p(\textbf{y}|\textbf{x})}[p(C|\textbf{x},\textbf{y})]\simeq 0 E y ∼ p ( y ∣ x ) [ p ( C ∣ x , y )] ≃ 0 R ^ θ \hat{R}_{\theta} R ^ θ q ^ \hat{q} q ^ R ^ θ \hat{R}_\theta R ^ θ C C C q ^ \hat{q} q ^ p ( y ∣ x ) q ^ ( y ∣ x ) \frac{p(\textbf{y}|\textbf{x})}{\hat{q}(\textbf{y}|\textbf{x})} q ^ ( y ∣ x ) p ( y ∣ x )
E y ∼ q ^ ( t e x t b f y ∣ x ) [ p ( y ∣ x ) q ^ ( y ∣ x ) L C E ( x , y , R θ ) ] = ∑ y ∈ Y p ( y ∣ x ) L C E ( x , y , R θ ) \begin{aligned} \mathbb{E}_{\textbf{y}\sim \hat{q}(textbf{y}|\textbf{x})}[\frac{p(\textbf{y}|\textbf{x})}{\hat{q}(\textbf{y}|\textbf{x})}L_{CE}(\textbf{x},\textbf{y},R_{\theta})] =\sum_{\textbf{y}\in\mathcal{Y}}p(\textbf{y}|\textbf{x})L_{CE}(\textbf{x},\textbf{y},R_{\theta}) \end{aligned} E y ∼ q ^ ( t e x t b f y ∣ x ) [ q ^ ( y ∣ x ) p ( y ∣ x ) L CE ( x , y , R θ )] = y ∈ Y ∑ p ( y ∣ x ) L CE ( x , y , R θ )