测试
read3 测试
1.课程目标
- 理解测试的意义,并了解”测试有限编程“的过程
- 能够使用”分区“的方法选择合适的输入输出测试用例
- 能够通过代码覆盖率来评价一个测试的好坏
- 能够理解黑盒/白盒测试、单元/综合测试、自动化回归测试
2.验证
”测试“是”验证“的一种例子,而验证的目的就是发现程序中的问题,以此提升你对程序正确性的信心。
验证包括:
- 形式推理,即通过理论推到证明程序的正确性。
- 代码审查,即让别人仔细的阅读、审校、评价你的代码,这也是发现bug的一个常见方法。
- 测试,即选择合适的输入输出用例,通过运行程序检查程序的问题。
3.软件测试的难点
尽力测试(尝试所有可能):这通常不可行,因为大多数情况下输出的空间非常大,仅仅是一个浮点数乘法a*b,其总共的取值就有2^64中可能。
随机测试:这通常难以发现bug,除非这个程序到处都是bug以至于随便一个输入都能崩溃。随即测试不能使我们对程序的正确性很确定。
基于统计方法的测试:这种方法对软件不那么奏效。
4.测试优先编程(Test-first Programming)
测试开始的时间应该尽量早,并且要频繁的测试。
在测试优先编程中,测试程序先于代码完成。编写一个函数应该按如下步骤进行:
- 为函数写一个规格说明。
- 为上一步的规格说明写一些测试用例。
- 编写实际代码。一旦你的代码通过了所有你写的测试用例,这个函数就算完成了。
规格说明描述了这个函数的输入输出行为。它确定了函数参数的类型和对他们所有约束。(例sqrt函数的参数必须使非负的)他还定义了函数的返回值类型以及返回值和输入之间的关系。
先完成测试用例的编写能够让你更好的理解规格说明。规格说明也可能存在问题--不正确、不完整、模棱两可、确实边界情况。 因此先尝试编写测试用例,可以在你浪费时间实现一个有问题的规格说明之前发现这些问题。
函数规格说明举例:
/**
* 方法的简述
* 方法详细说明第一行
* 方法详细说明第二行
* @param 对方法中的参数的说明
* @return 对方法返回值的说明
* @exception 对方法可能抛出的异常进行说明
* public int method(int a){
* b = b + 1;
* return b;
* }
*/
第一部分是简述。简述写在一段文档注释的最前面。第一个点号前为简述,点号后为第二、三部分。
第二部分是详细说明部分,该部分对属性或者方法进行详细的说明,在格式上没有什么特殊的要求,可以包含若干个点号。
第三部分是特殊说明部分。这部分包含版本说明、参数说明、返回值说明等。
javadoc的标记由“@”及其后所跟的标记类型和专用注释引用组成。
javadoc标记有如下:
- @author 标明开发该类模块的作者
- @version 标明该类模块的版本
- @see 参考转向,也就是相关主题
- @param 对方法中某参数的说明
- @return 对方法返回值的说明
- @exception 对方法可能抛出的异常进行说明
@author可以多次使用,指明多个作者,每个作者之间使用逗号隔开。
@version也可以使用多次,但只有第一次有效。
注释文档将用来生成HTML格式的代码报告,所以注释文档必须书写在类、域、构造函数、方法、定义之前。注释文档由两部分组成--描述、块标记。
(后续会详细展开)
5.通过分区的方法选择测试用例
选择合适的测试用例是一个具有挑战性,但是有缺的问题,我们既希望测试空间足够小,以便快速完成测试,有希望测试用例能够验证尽可能多的情况。
为达到这个目的,我们将输入空间划分为几个子域(subdomains),每一个子域都是一类相似的数据。如图,我们在每个子域中选取一些数据,他们合并起来就是我们需要的输入用例。
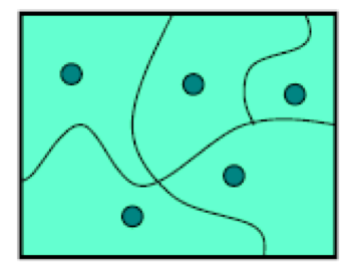
分区背后的原理在于同一类型的数据,在程序中的行为大多类似,因此我们可以用一小部分代表整体行为。这个方法的优点在于强迫程序相应输入空间里的不同地方,有效利用测试资源。
如果我们要确保测试的输出能够覆盖输出空间的不同地方,也可以将输出空间划分为几个子域,大多数情况下,对输入分区就足够了。
例:
/**
* @param val another BigInteger
* @return a BigInteger whose value is (this * val)
*/
public BigInteger multiply(BigInteger val)
例如,计算ab的值:
BigInteger a = ...;
BigInteger b = ...;
BigInteger ab = a.multiply(b);
这个例子显示即使只有一个参数,这个参数实际上有两个操作符:你调用这个方法所在的对象(上面是a),以及你传入的参数(上面是b)。
multiply:BigInteger x BigInteger -> BigInteger
所以我们的输入空间是二维的,用二位点阵(a,b)表示,现在我们对其分区,想一想乘法是怎么工作的,我们可以将点阵初步分为以下四个区:
- a、b都是正整数
- a、b都是负整数
- a是正整数、b是负整数
- a是负整数、b是正整数
这里也有一些特殊的情况要单独分出来:0 1 -2
- a或b是1\0-1
最后我们还要想一想BigInteger的乘法可能是怎么运算的,它可能在输入数据绝对值较小的时候,使用int或long,这样运算起来会快一些,只有当数据很大的时候,才采用更复杂的存储方法。
因此,我们也应该将数据的大小进行分区。
- a或b较小
- a或b的绝对值大于Long.MAX_VALUE,即Java原始整形的最大值。 现在,我们可以将上面划分的区域整合起来,得到最终划分的点阵:
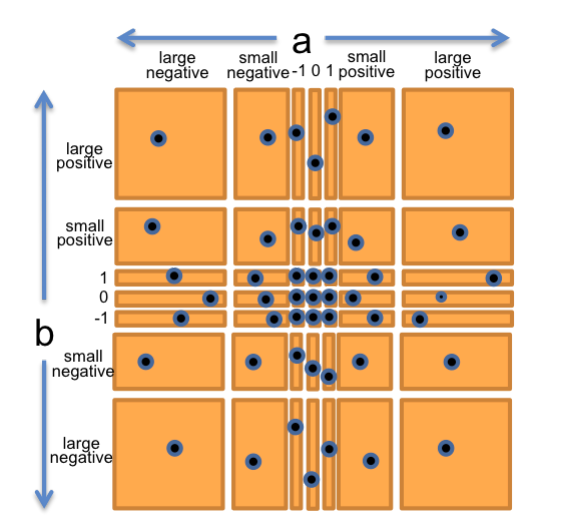
- 0
- 1
- -1
- 较小正整数
- 较小负整数
- 大正整数
- 大负整数 故我们可以得到7*7=49个分区,他们完全覆盖了a、b组成的所有输入空间。
注意分区之间的“边界”
bug经常会在各个分区的边界发生,例如:
- 在正整数和负整数之间的0
- 数字类型的最大值和最小值,例如int和double
- 空集,例如空的字符串,空的列表,空的数组
- 集合类型中的第一个元素或最后一个元素
覆盖分区的两个极限情况
在分区后,有两个极限情况:
完全笛卡尔乘积: 即对每一个存在组合都进行测试。
每一个分区被覆盖即可: 即每个分区至少被覆盖一次。
实际测试中,我们通常在这两个极限中折中。
6.使用JUnit做自动化单元测试
一个良好的测试程序应该测试软件的每一个模块(方法或类)。如果这种测试每次是对一个鼓励的模块单独进行的,那么这就成为“单元测试”。单元测试的好处在于debug,如果你发现一个单元测试失败了,那么debug很可能在这个单元内部,而不是软件的其他地方。
JUnit是Java中一个被广泛使用的测试库。
一个JUnit测试单元是以一个方法(method)写出的,其首部有一个@Test声明。一个测试单元通常含有对测试的模块进行的一次或多次调用,同时会用断言检查模块的返回值,比如assertEquals,assertTrue,assertFalse
例:
@Test
public void testALessThanB () {
assertEquals (2, Math.max(1, 2));
}
@Test
public void testBothEqual () {
assertEquals (9, Math.max(9, 9));
}
@Test
public void testAGreaterThanB () {
assertEquals (-5, Math.max(-5, -6));
}
assertEquals的参数,第一个应该为期望值,第二个参数为我们要进行的测试。
我们应该在测试时记录下我们的测试策略,例如如何分区,有哪些特殊值、边界等。
例如:
/*
* Testing strategy
*
* Partition the inputs as follows:
* text.length(): 0, 1, > 1
* start: 0, 1, 1 < start < text.length(),
* text.length() - 1, text.length()
* text.length()-start: 0, 1, even > 1, odd > 1
*
* Include even- and odd-length reversals because
* only odd has a middle element that doesn't move.
*
* Exhaustive Cartesian coverage of partitions.
*/
// covers test.length() = 0,
// start = 0 = text.length(),
// text.length()-start = 0
@Test public void testEmpty() {
assertEquals ("", reverseEnd ("", 0));
}
并且在每一个测试方法上放写下小注解,告诉读者,这个测试方法代表我们测试策略中的那一部分。
例:以下为一个完整的规格说明、方法的测试策略、每一个测试方法的注解:
现在假设我们要测试reverseEnd这个模块:
/**
* Reverses the end of a string.
*
* For example:
* reverseEnd("Hello, world", 5)
* returns "Hellodlrow ,"
*
* With start == 0, reverses the entire text.
* With start == text.length(), reverses nothing.
*
* @param text non-null String that will have
* its end reversed
* @param start the index at which the
* remainder of the input is
* reversed, requires 0 <=
* start <= text.length()
* @return input text with the substring from
* start to the end of the string
* reversed
*/
static String reverseEnd (String text, int start)
我们应该在测试时,记录下我们的测试策略,例如,如何分区,有哪些特殊值、边界值:
/*
* Testing strategy
*
* Partition the inputs as follows:
* text.length(): 0, 1, > 1
* start: 0, 1, 1 < start < text.length(),
* text.length() - 1, text.length()
* text.length()-start: 0, 1, even > 1, odd > 1
*
* Include even- and odd-length reversals because
* only odd has a middle element that doesn't move.
*
* Exhaustive Cartesian coverage of partitions.
*/
另外,每一个测试方法都要有一个小的注解,告诉读者这个测试方法是代表我们测试策略中的哪一部分,例如:
// covers test.length() = 0,
// start = 0 = text.length(),
// text.length()-start = 0
@Test
public void testEmpty() {
assertEquals ("", reverseEnd ("", 0));
}
7.黑盒测试、白盒测试
黑盒测试:只依据函数的规格说明来选择测试用例,而不关心函数是如何实现的。
白盒测试:在考虑函数的实际实现方法的前提下,选择测试用例。例如,若函数的视线中,对不同的输入采用不同的算法,那么你应该根据这些不同的区域来分类;如果一个代码实现中,维护一个内部缓存来记录之前得到的输入的答案,那你一个测试重复的输入。
8.覆盖率
一种判断测试的好坏的方法就是看该测试对软件的测试程度。这种测试程度也成为“覆盖率”,以下是常见的三种覆盖率:
- 语句覆盖:要求程序中的语句都执行一遍;
- 分支覆盖:要求程序中所有判定的分支尽可能得到检验;
- 条件覆盖:要使得每个判断中的每个条件的可能取值至少满足一次;
- 路径覆盖:要求覆盖程序中所有可能的路径.
例如:
boolean A = true;
boolean B = true;
boolean C = true;
boolean D = true;
if (A && B) {
System.out.println("分支1");
} else {
System.out.println("分支2");
}
if (C || D) {
System.out.println("分支3");
} else {
System.out.println("分支4");
}
语句覆盖:只要程序的语句都执行以便即可,A=true,B=true,C=true. 分支覆盖:使程序每个判断取真分支和取假分支至少一次,(1) A=true,B=true,C=true(2)A=false,C=false,D=false 条件覆盖:使得每个判断中的每个条件的可能取值至少满足一次,A、B、C、D,至少取一次true,取一次false,(1)A=true,B=true,C=true,D=true(2)A=false,B=false,C=false,D=false 路径覆盖:要求覆盖程序中所有可能路径,(1)A=true,B=true,C=true,D=true(2)A=false,B=true,C=true,D=true(3)A=true,B=true,C=false,D=false(4)A=false,B=true,C=false,D=false
Eclipse的代码覆盖率工具EclEmma
EclEmma会将被执行过的代码用绿色标出,没有被执行的代码用红色标出。对于一个分支语句,如果它的一个分支一直没有被执行,那么这个分支判断语句会被标为黄色。

9.单元测试、综合测试、桩
单元测试:对孤立的模块进行测试。当一个单元报错时,我们只需要在这个单元找bug,而不是在整个程序去找。
综合测试:对于组合起来的模块进行测试,甚至是整个程序。若综合测试报错,我们就只能在大的范围去找了。
但是综合测试是必要的,因为程序经常由于模块之间的交互而产生bug。
桩:集成测试前要为被测模块编制一些模拟其下级模块功能的“替身”模块,以代替被测模块的接口,接受或传递被测模块的数据,这些专供测试用的“假”模块称为被测模块的桩模块。 测试桩一般是自顶向下集成时需要使用。
10.自动化测试、回归测试
自动化测试:自动地运行测试对象,输入对应的测试用例,并记录结果的测试。
回归:修改代码后,带来新的bug的现象。
回归测试:在修改代码后,重新运行所有的测试。
一个好的测试应该能发现bug,应该不断充实测试用例,无论何时修改了一个bug,将bug的输入添加到测试用例,并在以后的回归测试中去使用它。
测试优先debugging的核心:当bug出现时,立即触发bug的输入存放到测试用例中,当你修复bug后,再运行这些测试。若都通过,则完成debug.
实践中,自动化测试、回归测试通常结合起来使用。因为回归测试只有自动化才可行。若已经构建了自动化测试,通常可以用来防止回归的发生,所以自动化回归测试是软件工程里的一个最佳实践。