语法分析
1. 自顶向下分析概述
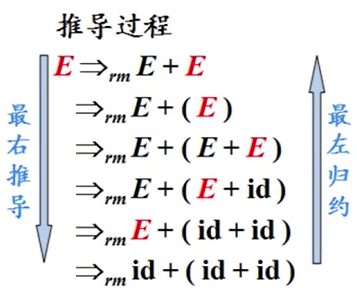
规范推导:最右推导
规范归约:最左规约
1.1 top_down步骤
- 消除歧义;
- 文法改造:
消除左递归
提取左公因子 - LL(1)文法的判定,确定性。
1.2 递归下降分析
模拟自顶向下建树过程,最左推导。
- 预测分析(确定的分析):LL(1)文法。
- 需要回溯的分析(不确定的分析)
2. 非递归的预测分析法
非递归预测分析不需要为每个非终结符编写递归下降过程,根据预测分析表构造自动机,也叫表驱动的预测分析。
2.1 文法转换
左递归文法会使递归下降分析器陷入无限循环。
直接左递归的文法:
A→Aα
经过两步或两步以上的推导产生的左递归是间接左递归的。
消除直接左递归:
A→Aα∣β(a=ϵ,β不以A开头)
替换为:
A→βA′
A′→αA′∣ϵ
消除左递归的一般形式:
A→Aa1∣Aa2∣...∣Aa3∣β1∣β2∣...∣βn∣(ai=ϵ,βj不以A开头)
替换为:
A→β1A′∣β2A′∣...∣β3A′
A′→a1A′∣a2A′∣...∣anA′∣ϵ
消除间接左递归
S→Aa∣b
A→Ac∣Sd∣ϵ
此时将S的定义代入A−产生式,得:
A→Ac∣Aad∣bd∣ϵ
消除A−产生式的直接左递归:
A→bdA′∣A′
A′→cA′∣adA′∣ϵ
2.2 FIRST集、SELECT集、FOLLOW集
FIRST集的对象是串。可以包含ϵ。
FOLLOW集的对象是非终结符。不可以包含ϵ。
SELECT集的对象是产生式。不可以包含ϵ。
FIRST集
个人理解:FIRST(A)为A能够推导出来的所有的终结符串位于串首的终结符构成集合,还要考虑A是否能够推导ϵ。
α的串首终结符集FIRST(α)集的定义为:
可以从α推导出来的所有串首终结符构成的集合。 若α→ϵ,那么ϵ也在FIRST(α)中。
SELECT集
个人理解:可以选用该产生式进行推导时对应的输入符号集合(终结符集合)。 若ϵ∈/FIRST(α),那么SELECT(A→α)=FIRST(α)
若ϵ∈FIRST(α), 那么SELECT(A→α)=(FIRST(α)−{ϵ})∪FOLLOW(A)
FOLLOW集 个人理解:FOLLOW(A)为由A产生的句型中紧跟在A后面的终结符。
定义:
FOLLOW(A)={a∣S→αAaβ,a∈VT,α,β∈(VT∪VN)∗}
若A是某个句型最右符号,则将结束符"$"添加到FOLLOW(A)中
算法:
- 将$放入FOLLOW(S)中,其中S为开始符号,$为输入右端的结束标记。
- 如果存在一个产生式A→αBβ,那么FIRST(β)中除了ϵ之外的所有符号都在FOLLOW(B)中。
- 如果存在一个产生式A→αB,或存在产生式A→αBβ,且FIRST(β)包含ϵ,那么FOLLOW(A)中的所有符号都在FOLLOW(B)中。
2.3 LL(1)文法
简洁定义:
∀A→α1∣α2∣...∣αn
SELECT(A→α1)∩SELECT(A→α2)∩...∩SELECT(A→αn)==∅
文法G是LL(1)的,当且仅当G的任意两个具有相同左部的产生式A→α∣β满足以下条件 (同一非终结符的各个产生式的可选集互不相交):
- 不存在终结符a使得α和β都能够推导出以a开头的串。
- α和β至多有一个能推导出ϵ。
- 若β→ϵ,则FIRST(α)∩FOLLOW(A)=∅
若α→ϵ,则FIRST(β)∩FOLLOW(A)=∅
2.4 LL(1)文法非递归下降分析
根据SELECT集构造预测分析表,进而实现确定的下降分析。
3. 自底向上的语法分析
3.1 LR分析法
工作过程:

- ACTION[sm,ai]=sx

- ACTION[sm,ai]=rx,则用第x个产生式A→Xm−(k−1)...Xm进行归约。

GOTO[sm−k,A]=y
进而有

- ACTION[sm,ai]=acc,则表示分析成功。
- ACTION[sm,ai]=error,则表示出现语法错误。
3.2 增广文法
如果G是一个以S为开始符号的文法,则G的增广文法G′就是在G中加上新开始符号S′和产生式S′→S而得到的文法。

目的:使文法开始符号仅出现在一个产生式的左边,从而使得分析器只有一个接收状态。
3.3 CLOSURE、GOTO函数及LR(0)项集族
计算给定项目集的闭包:
CLOUSURE(I)=I∪{B→⋅γ∣A→α⋅Bβ∈CLOSURE(I),B→γ∈P}
返回项目集I对应于文法符号X的后继项目集闭包:
GOTO(I,X)=CLOSURE({A→αX⋅β∣A→αXβ∈I})
规范LR(0)项集族:
C={I0}∪{I∣∃J∈C,X∃VN∪VT,I=GOTO(J,X)}
3.4 LR(0)分析表构造算法

3.5 SLR分析法
LR(0)存在移进归约冲突,可以根据FOLLOW集进行移进、归约操作。
与LR(0)的区别:SLR分析表,只有遇到他的FOLLOW集的元素才进行归约。
以A→α⋅∈Ii且A=S′ LR(0)分析法中,采取归约动作,而SLR分析法中,仅仅对于FOLLOW集中的元素归约。
存在的问题:SLR仅简单的考察下一个输入符号b是否与归约项目A→α相关联的FOLLOW(A),但b∈FOLLOW(A)只是归约α的一个必要条件,而非充分条件。
3.6 LR(1)分析法
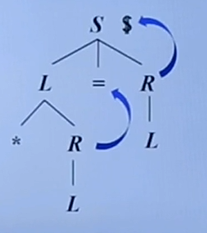
在特定位置中,A的后继符号集合是FOLLOW(A)的子集,如图,分析树中S的右节点R的后继符只能为$,而对于L的右节点,只有当下一个符号为=时,才能将L规约为R,我们采用L→∗R⋅,=。
规范LR(1)项目:将一般形式为[A→α⋅β,a]称为LR(1)项,其中[A→αβ是一个产生式,a是一个终结符,($为一个特殊的终结符),他表示在当前状态下,A后面必须紧跟终结符,称为该项的展望符。
当A→α⋅β,a中β=ϵ时,展望符没有任何作用
对于A→α⋅β,a只有在下一个符号为a时,才能进行归约,a总是FOLLOW(a)的子集,而且通常为真子集
构造算法:构造算法,对规约项目,只针对给定的后继符号归约。 